


This article is a continuation of Part I (A comprehensive guide to migrating from Python 2(Legacy Python) to Python 3), which details the changes, and improvements in Python 3, and why they are essential. The rest of the article describes automated tools, strategies, and the role of testing in the migration from Python 2 to 3.
Automated Tools for Migrating from Python 2 to 3
This section details and compares popular automatic tools used for Python 2 to 3 conversion. They can save you a lot of time by not having to manually check every print statement or string literal in your code. The least these tools can do is highlight what places would need to change to be compatible with Python 3.
2to3
2to3 is a python script that applies a series of fixers to change Python 2 code to valid Python 3 code. Let’s take a look at a small example taken from documentation —
#test.pydef greet(name):
print "Hello, {0}!".format(name)print "What's your name?"
name = raw_input()
greet(name)
Running 2to3 test.py gives out the diff against the original code. They can persist in filing using the -w flag.
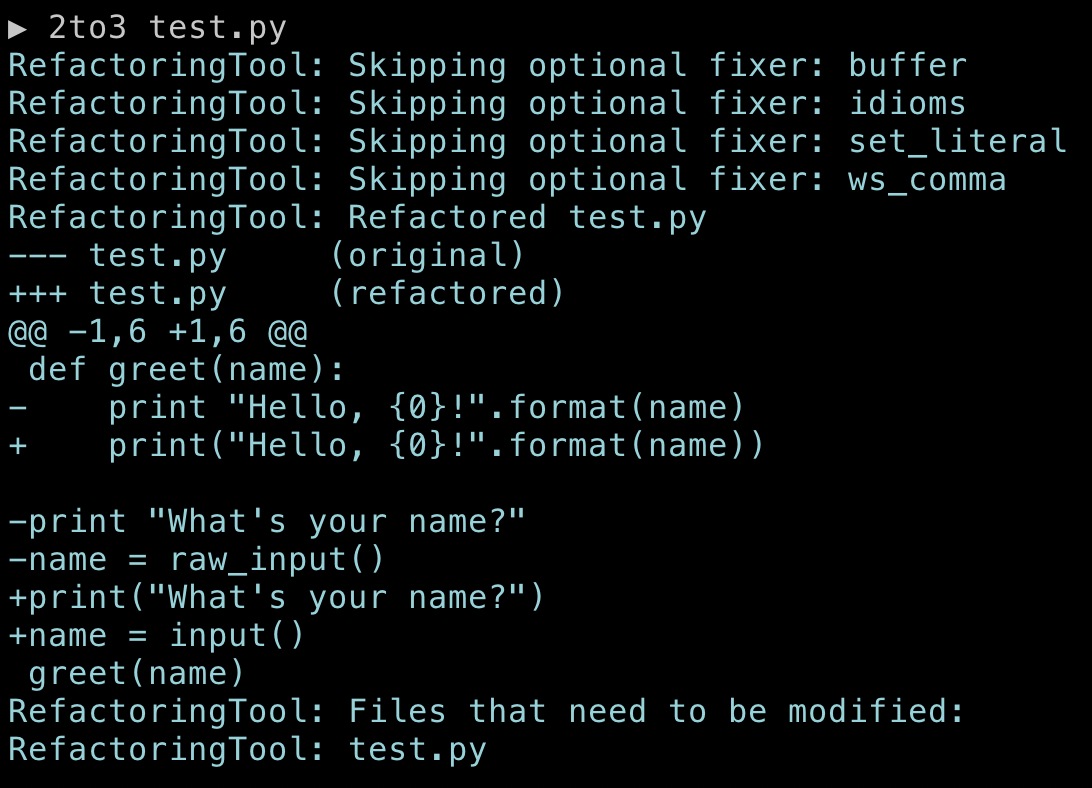
2to3 example
Each step of transforming code is encapsulated in a fixer. Each of them can be turned on/off individually using the -l flag. It is also possible to write your own fixers through lib2to3, the supporting library behind the tool.
The con with using 2to3 is that it is a one-way street; you cannot make your code run both on Python 2 and 3 at the same time. It has to be running on 3, which might not be possible for huge codebases to shift to right away.
2*3 = Six
In the migration process, most of the codebases running Python 2 on production, would want their code to keep running. You can introduce Python 3 support, but you still need your code to work on Python 2.
Six libraries provide a simple utility to wrap the differences between Python 2 and 3. It is intended to support codebases running on both Python 2 and 3 without modification. Let’s take a look at some essential utilities provided by six. A full list is available in Six’s official documentation.
# Booleans representing whether code is running Python 2 or 3
six.PY2
six.PY3# In Python 2, this is long and int, and in Python 3, just int
six.integer_types# Strings data, basestring() in Python 2 and str in Python 3
six.string_types# Coerce s to binary_type
six.ensure_binary(s, encoding='utf-8', errors='strict')# Coerce s to str
six.ensure_str(s, encoding='utf-8', errors='strict')# Six provides support for module renames and STL reorganization too# To import html_parser in Python 2(HTMLParser) and 3(html.parser)
from six.moves import html_parser# To import cPickle(Python 2) or pickle(Python 3)
from six.moves import cPickle
Python-Modernize
python-modernize is a utility based on 2to3, but uses six as a runtime dependency to give out a common subset of code running both on Python 2 and Python 3. It works in the same way as the 2to3 command-line utility.
Python Future
python-future, a library that allows you to add a compatibility layer between Python 2 and 3.x with minimal overhead. You would have a clean codebase running on Python 3 as well as Python 2.
It provides future and past packages with backports and forward ports of features from Python 3 and 2. It also comes with command-line utilities similar to 2to3 named futurize and pasteurize which lets you automatically convert code from Python 2 or Python 3 module by module, to maintain a clean Python 3 style codebase supporting both 2 and 3.
python-future and futurize is similar to six and python-modernize but it has a higher level compatibility layer than six. It has the further goal of allowing standard Python 3 code to run with almost no modification on both 3 and 2. We’ll look at the differences towards the end.
Let’s check out some simple examples of making code compatible using python-future —
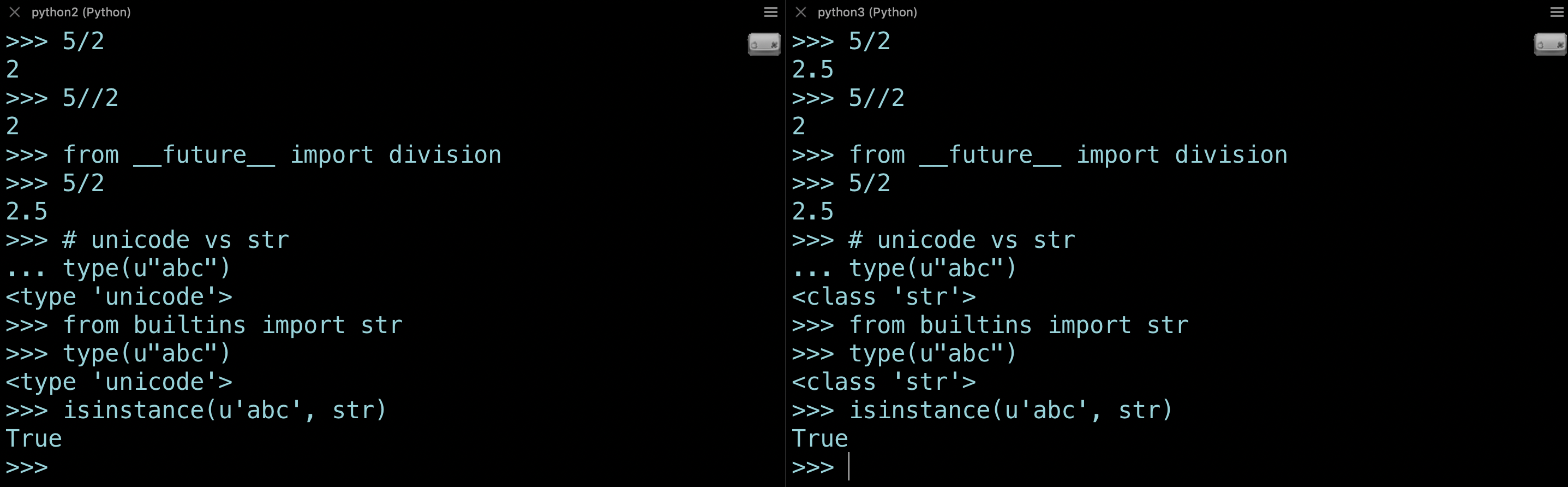
Basic examples(division and str) of using python-future
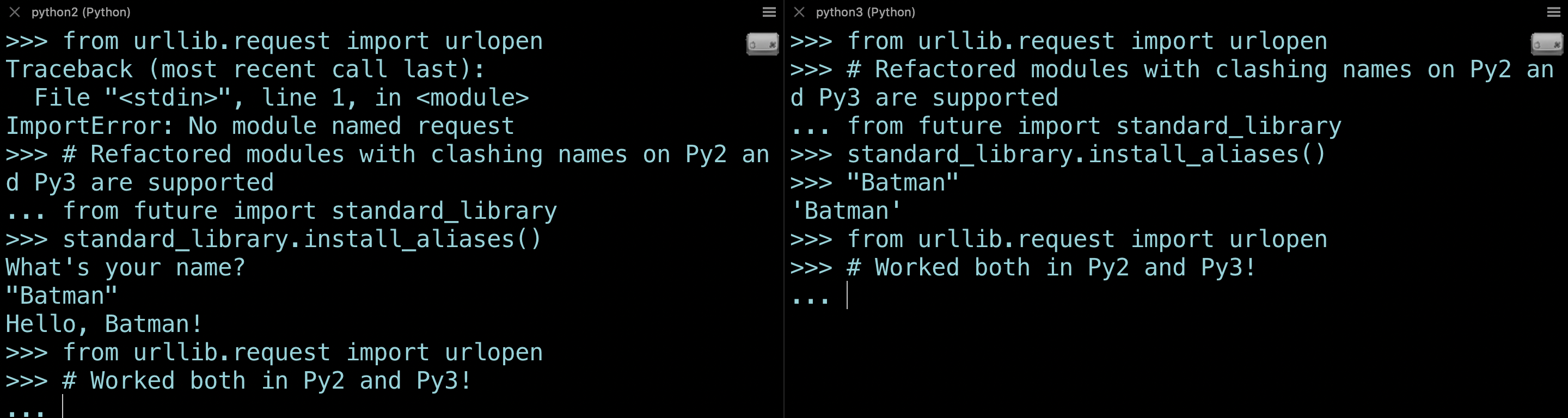
Using STL aliases
futurize works in two stages — It first applies the 2to3 fixtures to convert Python 2 code to 3 and then adds the __future__ and future module imports so that it works with 2 as well. It also handles the standard library reorganization(PEP-3108).
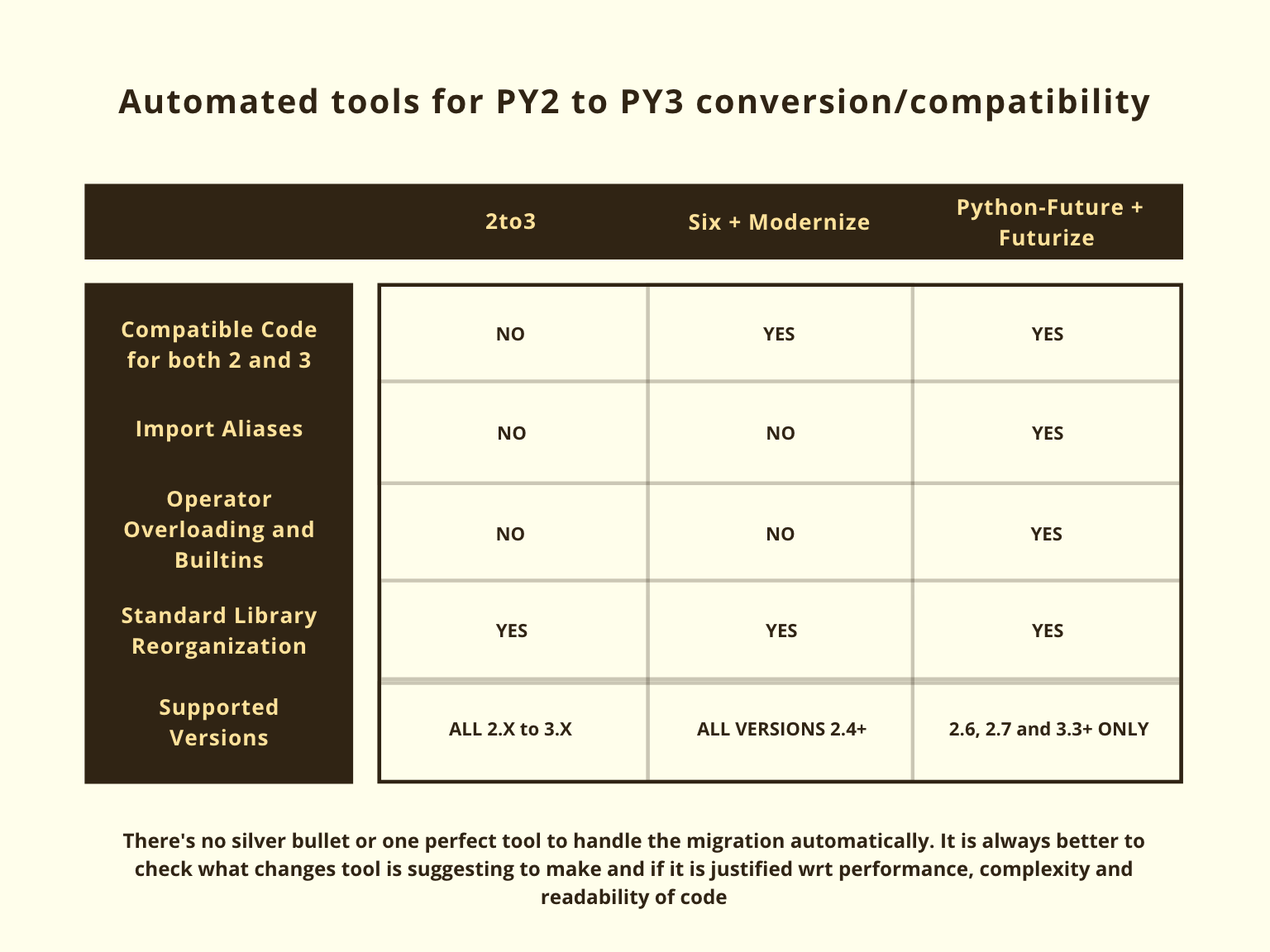
The Silver Bullet
These tools might seem like a silver bullet to migrate the whole codebase running on Python 2 to Python 3, but there is a catch — They may not always do the right thing. For example, using python-future for a line of code where you’re iterating over elements of a dict using dict.itervalues() will convert it to list(dict.itervalues()) which defeats the whole purpose of returning views instead of lists for performance improvements.
If your application is performance-critical, you might want to handle this differently. This is a straightforward example; there are more examples where a tool does something that works; however, you might have wanted it handled differently. The best way of using these tools would be to always look at what they’ll change in a module, discuss the changes with the dev team for performance, readability, complexity then write them back to the file as needed.
Strategies for Migration
We’ll discuss two major approaches to the process of migration. The right one depends on factors like the size of the codebase, developer bandwidth, and need of a functioning application at all times.
Rewrite the modules in Python 3 from scratch
If your application is small and can be refactored quickly, starting fresh and re-writing the code using Python 3 could be one viable approach. It’ll allow you to use all the new features provided by Python 3 right away and allow you to re-write the pieces you’ve wanted to improve.
It also helps with the overhead of writing and managing code compatible with both 2 and 3, and you cannot use the new Python 3 features until your application has migrated completely.
Have a balanced approach
If the application is significant and works on a decent scale and you have a large team working on different parts of the code base, you will need a functioning application at all times. Product engineers would also want to push new features alongside a set team of developers working on migrating the code from 2 to 3.
Here are some high-level steps for beginning with the migration process —
- Ensure that all the new code is Python 2 and 3 compatible with proper unit test case coverage.
- Plan the changes well. Decide a module, package, or microservice you’d want to start with.
- Take a look at the dependencies and packages you’d need to upgrade for Python 3 support. Most of the packages updated versions support Python 3, or there would be most likely a Python 3 alternative to those which were abandoned.
- Use one of the automated tools or linters to identify the changes you’d need to make to your code. Discuss those with the team for the need, performance and complexity.
- Once you do a change compatible with both Python 2 and 3, make sure to fix the unit test cases to work with both Python 2 and 3. Use
toxto run your tests in the two separate Python environments.toxIs discussed in the following section on the importance of having tests during migrations. - Make sure the code going into the master branch passes the test cases written for both Python 2 and 3. It’d be helpful to add a new step of running all test cases in Python 3 in the CI or release pipeline.
Usually, in organizations, releases are done under feature flagging or percentage rollout to users on production instead of immediately rolling out to 100% of traffic. Once the migration of a module is complete, it could be first released to the developers or users within the organization, then to beta and then to the rest of the users.
This helps as most of the bugs will be identified during the initial development and beta phases. After the rollout is 100% done and working, compatibility code can be deleted, and you are able to use the new features of Python 3. This approach was taken by Instagram to migrate their huge codebase to Python 3 with zero downtime.
Importance of testing in migrations
Tests are an essential part of the software development life cycle. If your application has good unit test case coverage, you can confidently refactor your code and not worry about repercussions.
In the migration from Python 2 to 3, an essential first step would be to check the percentage of code covered using some tool(Ex — coverage.py) by unit tests and maximizing the same by writing more test cases. This investment speeds up the development cycle in the long run. It’ll enable you to handle a change as small as a string update to as significant as Python 3 to 4(which could be coming 😛)
With a decent test coverage in place, you could use tox — a package that lets you run tests on different python versions in isolated virtual environments. It can also be integrated with popular CI pipelines like Jenkins, CircleCI, and Travis CI. You could also parallelize the whole test suite on different python versions using tox if it affects the speed of the release process.
Conclusion
In this article, we discussed the why and how of migrating from Python 2 to 3. We looked at the good things Python 3 has to offer. We explored some automated tooling to help with the migration process. Different strategies to approach the migration, and their pros and cons.
Migration from 2 to 3 is challenging but rewarding. The result is a better codebase, improved developer productivity, and performance. It gives you a solid foundation to scale for the next few years, at least. You’d also be able to contribute back to the open-source Python community, which is making sure it keeps getting better and better over time.






