


The N+1 Queries Problem is a perennial database performance issue. It affects many ORM’s and custom SQL code, and Django’s ORM is not immune either.
In this post, we’ll examine what the N+1 Queries Problem looks like in Django, some tools for fixing it, and most importantly some tools for detecting it. Naturally, Scout is one of those tools, with its built-in N+1 Insights tool.
What Is the N+1 Queries Problem?
In a nutshell: code that loops over a list of results from one query, and then performs another query per result.
Let’s look at a basic example and a couple of its natural extensions.
N+1 Queries
Say we had this code:
books = Book.objects.order_by("title")
for book in books:
print(book.title, "by", book.author.name)
This code uses print() for simplicity, but the problem exists in all other ways data might be accessed, such as in templates or views returning JSON responses.
Let’s trace the queries our code executes:
- One line 1, we create the
BookQuerySet. BecauseQuerySets are lazy, this doesn’t execute any query. - On line 2, we iterate over the
BookQuerySet. This causes theQuerySetto evaluate and fetch its results, which takes one query. - One line 3, we access a couple of attributes from each
Book.titleis a field on theBookitself, so Django fetched it in the first query. But theauthorattribute is a foreign key, so Django didn’t fetch it. Therefore Django executes another query on this line to fetch the givenAuthorcorresponding tobook.author_id. TheAuthorinstance then includes itsnamefield.
So we execute one query to fetch all the Books, and N queries to fetch the authors, where N is the number of books. This can become a performance problem because each query involves the overhead of communicating with the database server, so the total runtime can be high.
The problem is sometimes also called The 1+N Queries Problem to match the order of operations. N+1 seems to be a more popular name though, perhaps because it highlights problematic N queries.
From another perspective, we can look at the actual queries our code executes. The first query would look like:
SELECT
id,
title,
author_id,
...
FROM book
ORDER BY title
The following N author queries would look like:
SELECT
id,
name,
...
FROM author
WHERE id = %s
(With %s replaced by each author ID value.)
The repetition of queries like SELECT ... WHERE id = %s is a key signature of the problem. You can spot it with a tool that logs your application’s SQL queries (more these later).
2N+1 Queries
If we access multiple foreign key attributes in the loop, we’ll increase the number of queries. Say we changed the code to display our authors’ home countries as well:
books = Book.objects.order_by("title")
for book in books:
print(
book.title,
"by",
book.author.name,
"from",
book.author.country.name,
)
The access to author.country foreign key executes another query per loop. So we now have two times the N queries we had before.
NM+N+1 Queries
If we nest loops, we can execute multiple queries per N query, compounding the problem.
Imagine our models changed to allow multiple authors per book. We would adjust our code like so:
books = Book.objects.order_by("title")
for book in books:
print(book.title, "by: ", end="")
names = []
for author in book.authors.all():
names.append(f"{author.name} from {author.country.name}")
print(", ".join(names))
Line 5 executes each N query, fetching the list of authors per book. Line 6 then accesses the country foreign key per author. If there are an average of M authors per book, there will be N times M country queries.
Often either N or M is small, so the total number of queries will be fairly controlled. But it’s possible to see really large numbers of queries if both are bigger. If we added more nested loops, there would be further multiplication of queries.
Often such nested loops will not be so easy to spot. They can be obscured by intermediate layers of function calls or templates includes.
Tools to Fix the N+1 Queries Problem
Django provides two QuerySet methods that can turn the N queries back into one query, solving the performance issue. These methods are select_related() (docs) and prefetch_related() (docs).
They work similarly - both fetch the related model alongside the original query. The difference is that select_related() fetches the related instances in the same query, whilst prefetch_related() uses a second query. Let’s look at them in turn, then a bonus tool that can automatically use prefetch_related().
select_related()
Taking our first N+1 example, we can use select_related() by adding it to our Book QuerySet:
books = Book.objects.order_by("title").select_related("author")
for book in books:
print(book.title, "by", book.author.name)
Line 2 now executes a single query that selects both the Books and their related Authors. Line 3’s access of book.author no longer executes a query because the Author instance is already attached.
So we’ve optimized the code to execute only 1 query, instead of N+1.
The SQL with select_related() uses a JOIN to merge the two tables. The query will look something like this:
SELECT
book.id,
book.title,
book.author_id,
...,
author.id,
author.name,
...
FROM
book
INNER JOIN author ON (book.author_id = author.id)
ORDER BY book.title
Each row of the results table includes fields from both the book and author tables:
book.idbook.titlebook.author_idauthor.idauthor.name123The Hundred and One Dalmatians678678Dodie Smith234The Hound of the Baskervilles789789Arthur Conan Doyle345The Lost World789789Arthur Conan Doyle
One downside of this approach is that we might fetch duplicate author data. In the above example, the data includes two copies of Author ID 789, Arthur Conan Doyle. If an Author appeared a lot of times, or the model class had some large fields, the total data size would be large, and performance would suffer. In such cases, it’s better to use prefetch_related().Django loads the data into the correct model classes.
We can also fix our 2N+1 Queries example with select_related(), by declaring the chained relation:
Book.objects.order_by("title").select_related("author", "author__country")
Unfortunately select_related() cannot help us with the nested NM+N+1 queries example. select_related() can only work with one-to-one and one-to-many relationships, whilst that example has a many-to-many relationship between books and authors. Thankfully, prefetch_related() can work with many-to-many relationships.
prefetch_related()
Using prefetch_related() in our example looks much the same:
books = Book.objects.order_by("title").prefetch_related("author")
for book in books:
print(book.title, "by", book.author.name)
The difference is that line 2 now executes 2 queries. The first fetch the Books, and the second fetch the related Authors, without duplication. Django “joins” the fetched authors onto their respective Book instances in-memory. Line 3’s access of book.author again does not need to execute a query because the Author instance is attached.
In SQL, the first query is the same as without prefetch_related():
SELECT
id,
title,
author_id,
...
FROM book
ORDER BY title
Django iterates over the results and creates a set of the relevant author_id values. It uses this set in the second query:
SELECT
id,
name,
...
FROM author
WHERE id IN (%s, %s, ...)
This second query selects all the relevant authors in one go, using a list of their ID’s.
We can also fix our 2N+1 Queries example with prefetch_related():
Book.objects.order_by("title").prefetch_related("author", "author__country")
This executes three queries - one for the books, one for the authors, and one for the authors’ countries.
We can also fix our NM+N+1 Queries example:
Book.objects.order_by("title").prefetch_related("authors", "authors__country")
Note that prefetching a ManyToManyField only works if it is accessed with obj.field.all(). Any other QuerySet options, like adding an order_by(), require a new database query.
prefetch_related() has two key advantages over select_related().
First, it never fetches duplicated data. In our examples, each author is only ever fetched once from the database.
Second, it can fetch many-to-many and many-to-one relationships.
It varies by situation whether select_related() or prefetch_related() is optimal. If a function needs several related models, it may even be optimal to mix and match the two.
If in doubt, use prefetch_related(). Its two queries are unlikely to be much more expensive than the one from select_related(), and it works in all situations.
django-auto-prefetch
Here I’d like to highlight a special project, Django-auto-prefetch. Using this for your models changes Django’s behavior when accessing unfetched foreign keys.
Recall our first example:
books = Book.objects.order_by("title")
for book in books:
print(book.title, "by", book.author.name)
On line 3 Django fetches the single author relating to the current book. This happens on each of the N iterations of the loop.
Django-auto-prefetch changes this behavior to fetch all the authors relating to all the fetched books, in one query. It essentially assumes that since one book.author was required, they all will be.
This is equivalent to using prefetch_related() in the original Book QuerySet, hence the library’s name. It has the big advantage that we don’t need to know ahead of time which fields are required.
Installation of Django-auto-prefetch is slightly involved, as it requires swapping the base class for all your models. But it’s worth it on larger projects.
The library was created by my friend Gordon Wrigley. We hope to merge it into Django at some point, so the behavior would be more accessible. It might even eradicate the N+1 Queries Problem for Django applications.
Tools for Finding N+1 Query Problems
N+1 Query Problems are the most frequent Django ORM performance problem. It’s worth having some tooling that can help you find them. Let’s look at three tools that can help you.
Django-debug-toolbar
Django-debug-toolbar is one of the most popular third party Django packages. I don’t start a project without it. Once installed, it provides a debug panel on each view that shows us several panels of information, including the executed SQL queries.
For example, if we had our first example inside a view, the SQL panel would show our queries:
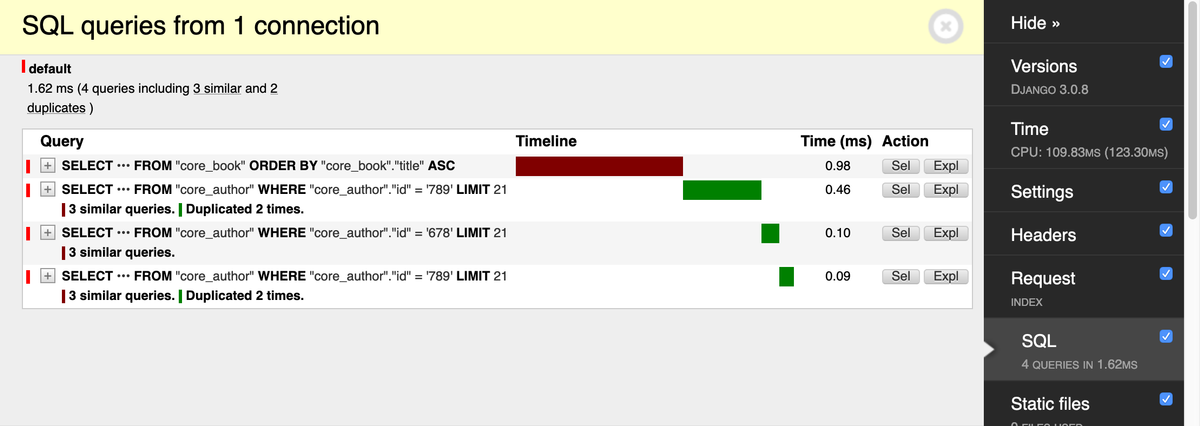
The panel highlights the N Author queries with the text:
3 similar queries. Duplicated 2 times.
We can expand the queries to see their full SQL and stack traces. This allows us to spot the problematic lines in our code.
Django-toolbar is very useful, and the SQL panel is only one of its features. But it has some limitations for finding N+1 Queries.
First, the toolbar can only appear on views that return HTML. This means you can’t use it to analyze views that return JSON, management commands, background tasks, etc. It can work with Django REST Framework’s Browsable API though since such views return HTML.
Second, using the toolbar requires you to know which pages are slow. It doesn’t provide any proactive protection - we need to remember to open and read the SQL panel on each page during development.
Finally, the toolbar is for development only. We can’t use it in production, which means we can’t inspect the performance issues that are affecting real users. Often the N is small in development and larger in production, so performance issues can appear only in production.
nplusone
The nplusone package logs warnings for potential N+1 Queries. The package works but seems slightly unmaintained, with no commits for two years.
After installing it, we can see several log messages for our example, interlaced with our print() statements:
Potential n+1 query detected on `Book.author`
The Hound of the Baskervilles by Arthur Conan Doyle
Potential n+1 query detected on `Book.author`
The Hundred and One Dalmatians by Dodie Smith
Potential n+1 query detected on `Book.author`
The Lost World by Arthur Conan Doyle
[30/Jul/2020 06:23:46] "GET / HTTP/1.1" 200 9495
These “Potential n+1 query detected” log messages can help us track down the problem.
nplusone is more focussed than Django-debug-toolbar but is also usable with other ORM’s, such as SQL Alchemy. It has many of the same limitations though.
We can use it for all views. But like Django-debug-toolbar, it can’t help with management commands, background tasks, and other code paths.
It’s always active but requires us to manually inspect the logs.
Unfortunately, the log message provides only a small amount of information. The log message provides no information about which line of our code is executing the N+1 Queries. We could get stack traces by configuring logging to transform the messages into exceptions, perhaps in development only. Though this may trigger false positives.
We can use nplusone in production. To receive notifications of problematic pages, we could configure our logging provider to alert on the string “Potential n+1 query detected”.
Scout APM
Scout APM automatically detects N+1 Queries in your application and is suitable for both development and production. It can trace any view, background task, or other code paths, and its traces provide rich information for debugging where performance issues occur.
Other APM (Application Performance Monitoring) products can also help with debugging N+1 Queries, but most don’t automatically highlight them.
After following the three-step Django installation guide for our example application and loading the problematic view, the N+1 Queries is highlighted on the dashboard:
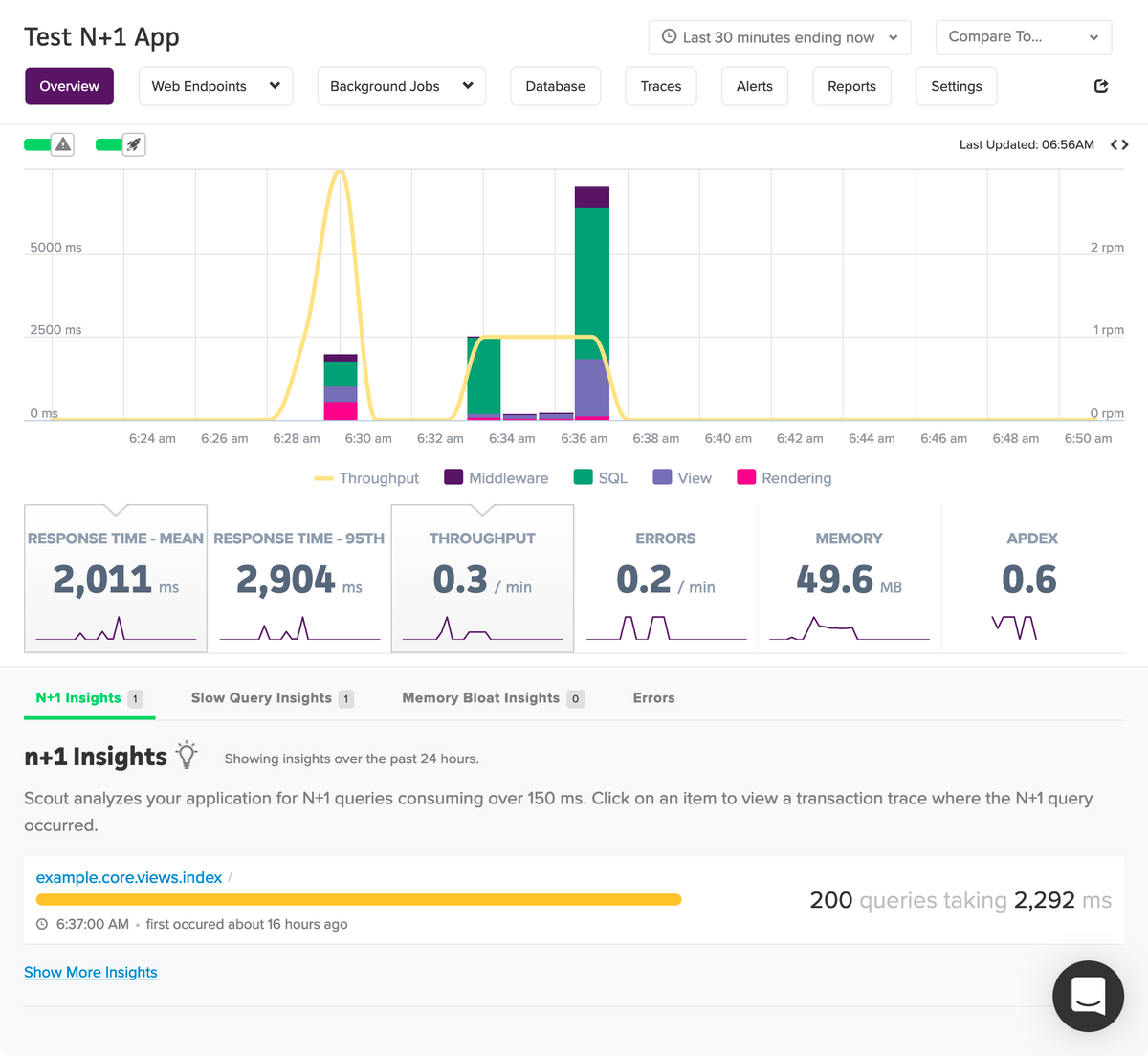
The top graph provides some insights into what our application is currently doing, and is followed by some useful summary statistics.
The “N+1 Insights” tab is what we’re here to look at. This tab lists views in which Scout detected N+1 Query execution. It uses a 150-millisecond threshold so we can focus on problems that really affect users.
If we click on the view name, we’re taken to the relevant trace:
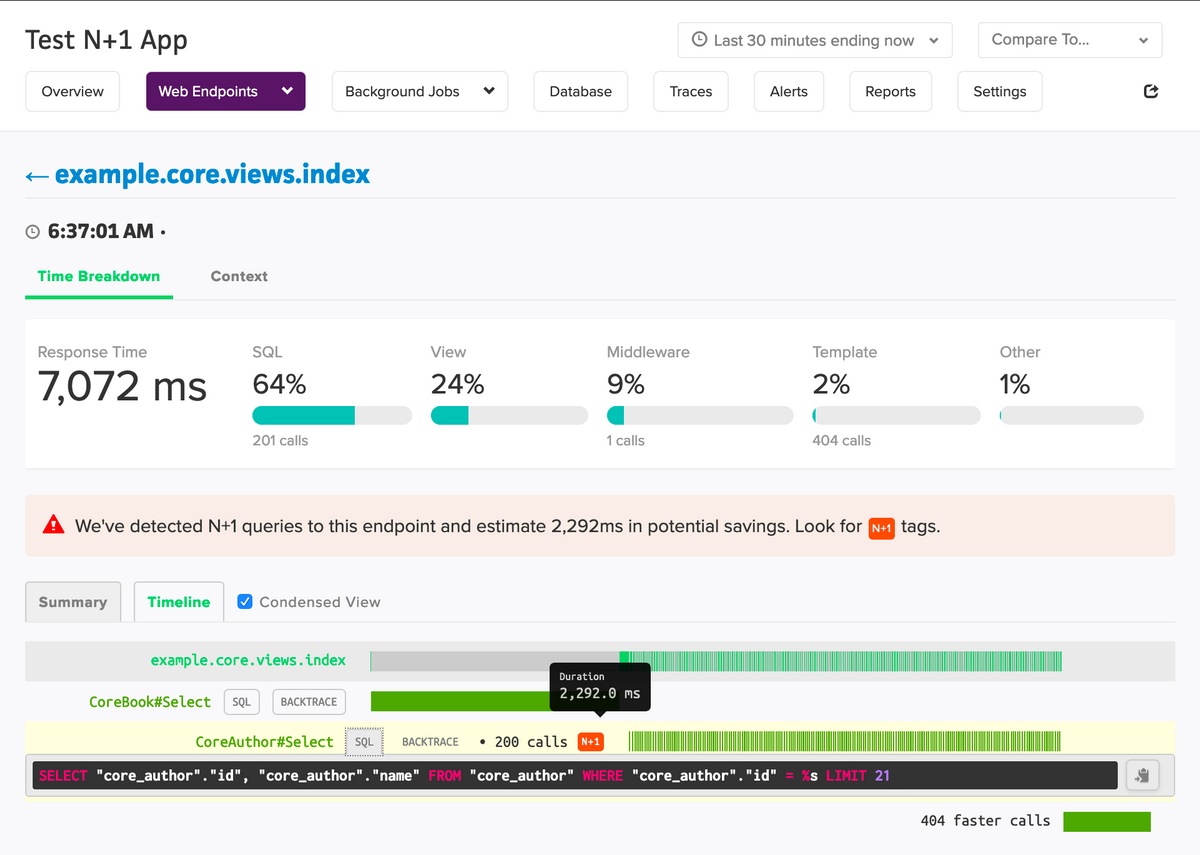
The trace shows a timeline of the view’s execution. The problematic repeated query has the “N+1” tag and shows the full SQL. We can click on its “backtrace” button to reveal the full stack trace, allowing us to pinpoint the problematic code.
Fin
I hope this guide has equipped you to find and solve your N+1 Query Problems,
—Adam







