MallocはマルチスレッドRubyプログラムのメモリ使用量を倍にする
ネイト・ベルコペック (@nateberkopec) SpeedShop(詳細),Railsパフォーマンス・コンサルタンシー
メモリの断片化は、測定したり、診断するのが難しいです。しかし、非常に簡単に解決できることも時々あります。マルチ・スレッドのCRubyプログラムのメモリの断片化の原因の一つについて見てみましょう。: mallocのスレッドごとのメモリ・アリーナ。
 本当に簡単な時もあります。
本当に簡単な時もあります。
単純な設定の変更が、問題を完全に解決できるとは限りません。
私の顧客のSidekiqプロセスが、大量のメモリ...一つにつき約1GBを使用していました。300MBで起動し、数時間を経て1GBに安定するまで、ゆっくり増えていっていました。
私は、環境変数を一つだけ変えるように頼みました:MALLOC_ARENA_MAXです。"これを2に設定してください"
プロセスを再起動し、使用量のゆっくりとした増加は、あっという間に解決しました。プロセスは、以前と比較して半分のメモリ使用量で安定しました...一つ当たりおおよそ512MBです。
 (字幕:嘘だよん)
(字幕:嘘だよん)
実際にはそれほど単純ではありません。無料のランチなどないのです。このケースでは10セントのランチのように無料に近いですが。
今、この"魔法"の環境変数を、あなたのアプリケーションの環境にコピー・ペーストしに行く前に、このことを理解してください:欠点があります。あなたは環境変数が解く問題に苦しんでいないかもしれないし、銀の弾丸など存在しないのです。
Rubyは、メモリ使用量が少ない言語とはみなされていません。 多くのRailsアプリケーションは、プロセスごとに最大1ギガ・バイトのメモリを使用します。 Javaのレベルに近づいています。 Rubyのバック・グラウンド・ジョブ・プロセッサとしてよく知られているSidekiqには、同じぐらい、もしくはさらに大量のメモリを使用するプロセスがあります。 様々な理由がありますが、一つは特に断片化の分析とデバッグが非常に難しいためです。
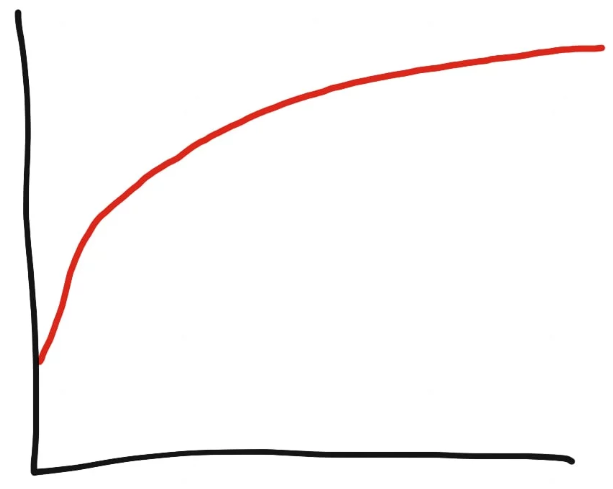 典型的にはRubyのメモリ使用量は対数で増加します。
典型的にはRubyのメモリ使用量は対数で増加します。
この問題は、Rubyプロセスに忍び寄る、ゆっくりとしたメモリ使用量の増加として現れます。 よくメモリリークと間違えられます。 しかしメモリ・リークとは異なります。メモリリークは線形ですが、断片化によるメモリの増加は対数です。
Rubyプログラムのメモリリークは、通常C言語拡張のバグによって発生します。例えば、Markdownパーサを呼び出すたびに10KBのリークが発生した場合、Markdownパーサは一定のの頻度でコールされる傾向があるため、メモリの増加は線形の割合で永久に続きます。
メモリの断片化によって、メモリは対数的に増加します。 長いカーブのように見え、目に見えない限界に近づいていきます。 すべてのRubyプロセスにはある程度メモリ断片化があります。 Rubyのメモリ管理方法によるもので、避けられない結果です。
具体的に説明すると、Rubyはメモリ内のオブジェクトを移動できません。Rubyオブジェクトへの生のポインタを持っているC言語拡張を破壊する可能性があります。 オブジェクトをメモリ内で移動できない場合、断片化は避けられない結果です。 Rubyだけではなく、C言語のプログラムでもよくある問題です。
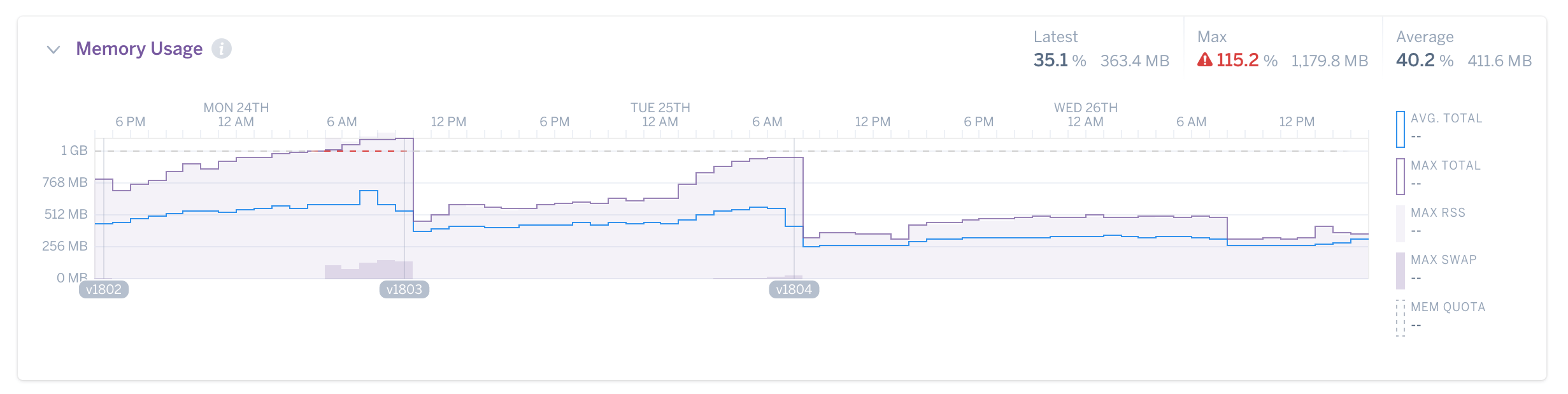
顧客の実際のグラフ。これが断片化の様子です。 MALLOC_ARENA_MAXが2に変更された後の大幅な低下に注目してください。
しかし、断片化により、Rubyプログラムが本来使用するメモリの2倍に、場合によっては4倍以上になることがあります!
Rubyプログラマはメモリについて考えるのに慣れていません。特にmallocのレベルではなおさらです。それでよいのです:言語全体がプログラマからメモリを抽象化するようにデザインされています。まさしくmanページにある通りです。しかしRubyはメモリの安全性を保証できますが、完璧なメモリの抽象化を提供することはできません。メモリについて完全に無関心ではいられません。Rubyプログラマはコンピュータメモリの動作についてナイーブで経験が浅いため、問題が発生した時にデバッグを開始する場所さえわからず、Rubyのような動的なインタプリタ言語では仕方のないことだと問題を無視することもあります。

(エンドウ豆の上に寝たお姫さま)「そして、4レイヤーのメモリ抽象化の下で、彼女はいくつかの断片化に気付きました!」
厄介なことに、メモリは4つの独立したレイヤを通じて、Ruby開発者から抽象化されています。1番目はRubyの仮想マシン自体で、独自の内部機構とメモリの追跡機能を持っています(時折ObjectSpaceと呼ばれます)。2番目はアロケーターです。使用している特定の実装によって、動作は大きく異なります。3番目はオペレーティング・システムです。実際の物理メモリを仮想メモリを通じて抽象化します。カーネルによってその方法は大きく異なります...例えば、MachとLinuxで大きく異なります。最後に、実際のハードウェア自体です。よくアクセスされるデータを、アクセスがより速い"hot"な場所に保持するために、様々なストラテジが使用されます。ここではトランスレーション・ルックアサイド・バッファ(translation lookaside buffer)のようなCPUの特別なパーツも含まれます。
Ruby開発者にとって、これらの事情がメモリ断片化を扱うことを難しくしています。メモリ断片化は、一般的に仮想マシンと、Ruby言語の一部であるアロケーターのレベルで起こる問題で、おそらく95%のRuby開発者は詳しくないでしょう。
多少のメモリ断片化は避けられません、しかしまた、Rubyプロセスのメモリ使用量を倍にして、状況を非常に悪くする可能性があります。前者ではなく後者に苦しんでいるかどうかを知るにはどうすればよいのでしょうか。何が重大なメモリ断片化の原因なのでしょうか。そうですね...PumaやPassenger Enterprise上で動作しているwebアプリケーションや、 SidekiqやSucker Punchなどのマルチ・スレッドのジョブ・プロセッサのような、マルチ・スレッドのRubyアプリケーションに影響するメモリ断片化の原因について、私は一つの考えを持っています。
glibc Malloc内のスレッドごとのメモリアリーナ
「スレッドごとのメモリアリーナ(Per-Thread Memory Arenas)」と呼ばれる、標準glibc malloc実装の特定の機能に、全ては集約されます。
理由を理解するために、非常に高速なCRubyのガベージ・コレクションがどの様に動作しているか、説明しましょう。
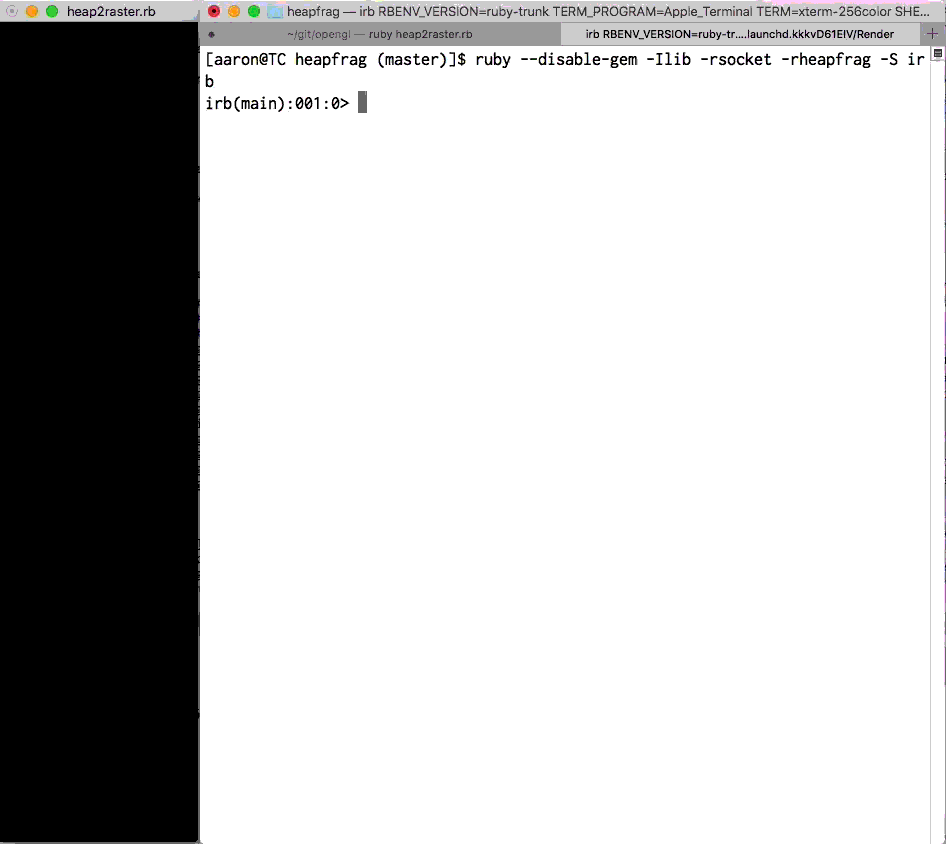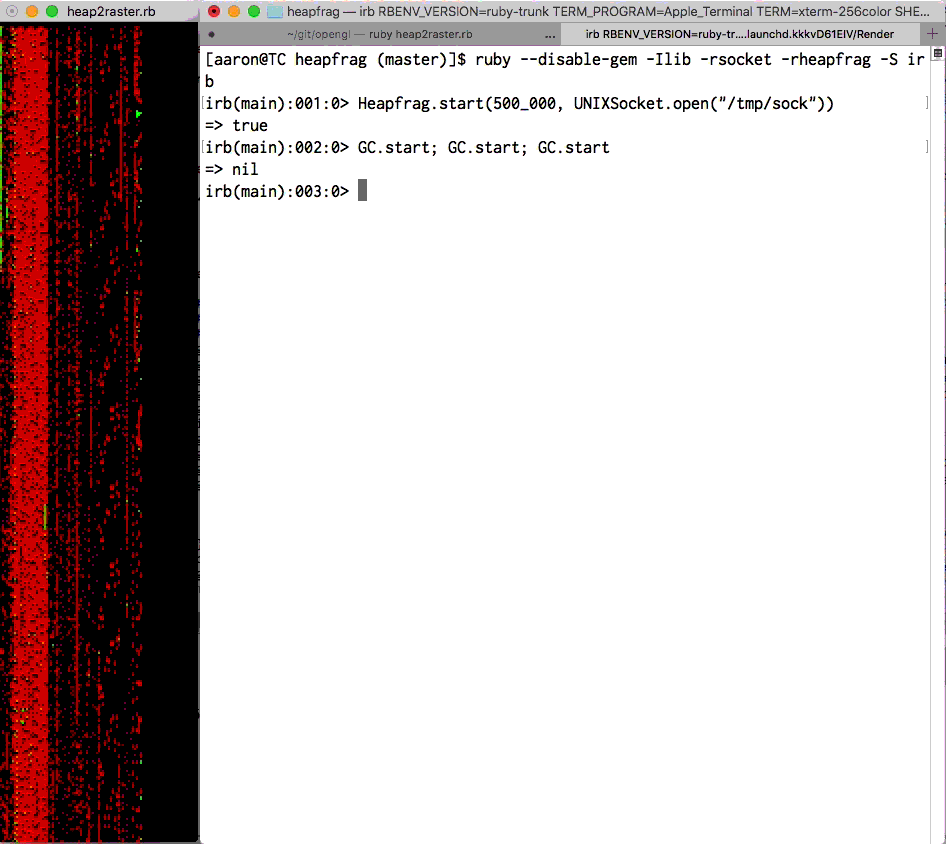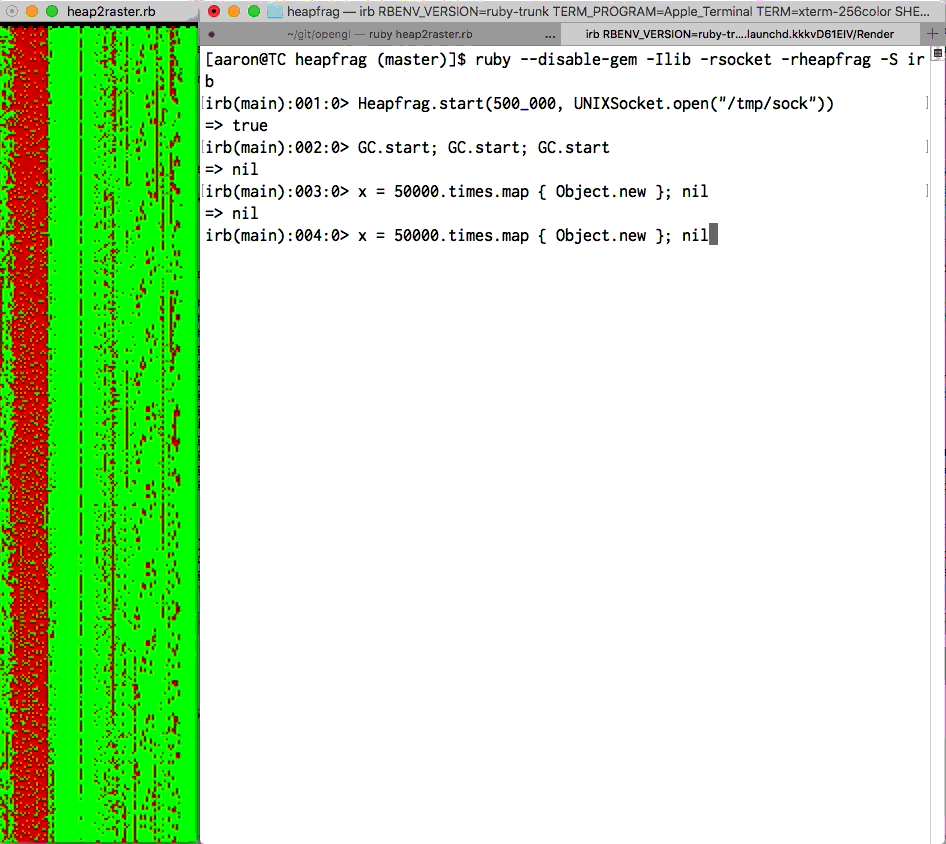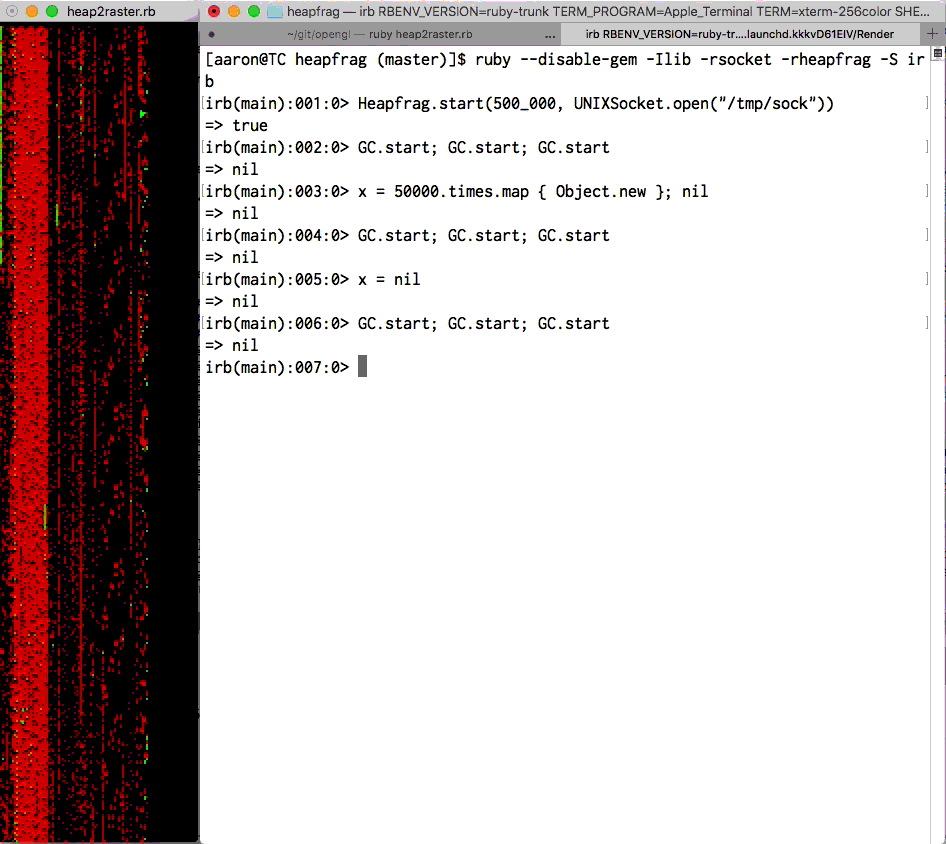
アーロン・パターソン(Aaron Patterson)によるObjectSpaceの視覚化。 各ピクセルはRVALUEです。 緑は”新しい”、赤は”古い”です。 heapfragを参照してください。
全てのオブジェクトはObjectSpaceにエントリを持っています。ObjectSpaceは巨大なリストで、現在実行されているプロセス内にある、各Rubyオブジェクトのエントリを保持しています。リストのエントリはRVALUEの形をとっており、40バイトのCの構造体です。オブジェクトに関する基本的な情報を保持しています。構造体の実際の内容はオブジェクトのクラスにより異なります。例として、"hello"のような非常に短い文字列であれば、キャラクタ・データを保持する実際のビットは、RVALUEに直接埋め込まれています。しかし40バイトだけなので...もし文字列が23バイトかそれより長い場合、RVALUEとは別の場所にあるメモリに、実際にレイアウトされた、オブジェクト・データへの生ポインタを保持するだけです。
RVALUEはさらに、ObjectSpaceの16KB"ページ"に整理されています。各ページはおよそ408のRVALUEを保持しています。
どのRubyプロセスでも、GC::INTERNAL_CONSTANTS定数を見て数を確認できます。
|
GC::INTERNAL_CONSTANTS => { :RVALUE_SIZE=>40, :HEAP_PAGE_OBJ_LIMIT=>408, # ... } |
長い文字列(例えば1000キャラクタのHTTPレスポンスとしましょう)を作成すると、以下のようになります:
- ObjectSpaceリストにRVALUEが追加されます。もしObjectSpace内に空いているスロットがなければ、 malloc(16384)をコールしてリストを1ヒープ・ページ分拡張します。
- malloc(1000) をコールして、1000バイトのメモリ領域(*1)へのアドレスを受け取ります。ここにHTTPのレスポンスが置かれます。
(*1 )実際には、文字列が追加されたり、サイズが変更されることに備え、Rubyは要求量より少し大きな領域をリクエストします。
ここでmallocコールに注意してください。どこかに特定サイズのメモリ領域を要求していますが、実はmallocの隣接性は定義されていません。つまりメモリ領域がどこにあるのか保証されません。Ruby VMの観点からみると、断片化(本質的にはメモリがどこにあるかの問題です)はアロケーターの問題だということです(*2)。
(*2 )しかし、アロケーションのパターンとサイズは、間違いなくアロケーターにとって対応するのが難しいですが。
Rubyは、ある意味、ObjectSpace自体の断片化を測定することができます。GCモジュールのメソッドGC statは、現在のメモリとGCステートの豊富な情報を提供します。少し情報に圧倒されますが下で説明します。出力は次のようなハッシュです。:
|
GC.stat => { :count=>12, :heap_allocated_pages=>91, :heap_sorted_length=>91, # ... way more keys ... } |
ハッシュの中の2つのキーをご覧ください:GC.stat[:heap_live_slots]とGC.stat[:heap_eden_pages]
:heap_live_slots refersは、ObjectSpace内で、現在RVALUE構造体に占有されている(解放とマークされていない)スロットの数です。大雑把に言って"現在生存しているRubyオブジェクトの数"です。
 エデン・ヒープ
エデン・ヒープ
:heap_eden_pagesは、使用中のスロットが少なくとも一つある、ObjectSpaceページの数です。使用中のスロットが少なくとも一つあるObjectSpaceページはエデン・ページ(Eden Page)と呼ばれます。ObjectSpaceページ一つも生存中のオブジェクトを保持していないObjectSpaceページはトゥーム・ページ(tomb pages)と呼ばれます。この区別はGCの観点からは重要です。トゥーム・ページはオペレーションシステムに返却することができるからです。またGCは新しいオブジェクトを先にエデン・ページに入れます。すべてのエデン・ページが埋まってからトゥーム・ページに挿入します。これで断片化が減ります。
使用中のスロット数を全てのedenページのスロット数で割ると、現在のObjectSpaceの断片化を計測することができます。 例として、下は私が新しいirbプロセスで得たものです:
|
5.times { GC.start } GC.stat[:heap_live_slots] # 24508 GC.stat[:heap_eden_pages] # 83 GC::INTERNAL_CONSTANTS[:HEAP_PAGE_OBJ_LIMIT] # 408 # live_slots / (eden_pages * slots_per_page) # 24508 / (83 * 408) = 72.3% (#使用中のスロット/(エデン・ページ数*ページ毎のスロット数)) (#24508/(83*408) =72.3%) |
エデン・ページのスロットの現在約28%は空いています。 空きスロットの割合が高いということは、ObjectSpaceのRVALUEは、動かせたと仮定した場合(訳注:動かせてきっちり詰まっていると仮定した場合)の本来の状態よりも、多くのヒープページに分散していることを示しています。 これは一種の内部メモリの断片化です。
Ruby VM内部の断片化のもう一つの基準はGC.stat [:heap_sorted_length]から来ています。
このキーはヒープの”長さ”です。3つのObjectSpaceページがあったとして、2番目のページ(中央のページ)をfreeすると、残りのヒープページは2つだけになります。 ただし、メモリ内でヒープ・ページを移動することはできないため、ヒープの”長さ”(基本的にヒープ・ページの最大インデックス)は3のままです。
 はい、このヒープは断片化していますが、本当に美味しそうです。
はい、このヒープは断片化していますが、本当に美味しそうです。
GC.stat [:heap_eden_pages]をGC.stat [:heap_sorted_length]で割ると、ObjectSpaceページのレベルで、内部の断片化を計測できます...低いパーセンテージは、ObjectSpaceリスト内にヒープ・ページ単位の”穴”が多いことを示します 。
これらの計測は興味深いものですが、ほとんどのメモリ断片化(とアロケーション)はObjectSpaceでは発生しません。一つのRVALUEに収まらないオブジェクトにスペースを割り当てるプロセスで発生します。 アーロン・パターソン(Aaron Patterson)とサム・サフラン(Sam Saffron)の実験によると、アロケーションのほとんどがそうだとわかりました。典型的なRailsアプリケーションのメモリ使用量は、数バイトを超えるオブジェクトにスペースを確保するためのmallocのコールが50〜80%を占めます。
NateのTwitter:https://twitter.com/tenderlove/status/879870368680255489
(むむ、これはひどい。どうやら 基本的なRailsアプリケーションのヒープは15%だけしかGCで管理されないようだ。85%は単なるmallocだ。)
ここで アーロンは”ObjectSpaceリスト内”という意味で、”GCによって管理されている”と言っています。
オーケー。それでは、どこでスレッドごとのメモリ・アリーナが出てくるのか、お話しましょう。
スレッドごとのメモリ・アリーナはglibc2.10で導入された最適化で、今日にいたるまでarena.cに存在しています。 メモリ・アクセス時にスレッド間の競合を減らすように設計されています。
ネイティブな基本アロケーターの設計では、アロケーターは一度に一つのスレッドだけが、メイン・アリーナからメモリ・チャンクを要求できるようにします。2つのスレッドが誤って同じメモリチャンクを取得しないことが保証されます。さもなければ、様々な、とても厄介なマルチ・スレッドのバグを引き起こすでしょう。しかし、スレッド数が多いプログラムでは、ロックに関して多くの競合があるため、遅くなる可能性があります。 全てのスレッドのための全てのメモリアクセスは、このロック経由になるため、どのようにボトルネックになりえるか、予想できると思います。
アロケーターの設計では、ロックの排除に大きな努力が払われています。パフォーマンスに影響があるからです。 ロックレス・アロケーターもあります。
スレッドごとのメモリ・アリーナの実装は、下記のプロセスによってロックの競合を軽減します(シドヘッシュ・ポヤレカル(Siddhesh Poyarekar)の記事を参考にしました)。
- スレッド内でmallocをコールすると、 スレッドは以前にアクセスしたメモリアリーナ(もしくは他のアリーナが作成されていない場合、メインアリーナ)のロックを取得しようとします。
- そのアリーナが利用できない場合、次のメモリアリーナを試します(他のメモリアリーナがある場合)。
- 利用可能なメモリ・アリーナがない場合は、新しいアリーナを作成して使用します。新しいアリーナは、リンク・リスト内の最後のアリーナにリンクされています。
このようにして、メイン・アリーナは基本的に、アリーナ/ヒープのリンク・リストを使用して拡張されます。 アリーナの数はmallopt、特にM_ARENA_MAXパラメータによって制限されます(ここにドキュメントがあります。”環境変数”セクションを参照してください)。デフォルトでは、スレッドごとのメモリ・アリーナの作成可能数は、利用可能なコアの数の8倍です。 ほとんどのRuby Webアプリケーションはコアあたり約5スレッドを実行し、Sidekiqクラスタでは、さらに多く実行することもあり得ます。これは実際に、多くの...多くのスレッドごとのメモリ・アリーナがRubyアプリケーションによって作成され得ることを意味しています。
マルチ・スレッドRubyアプリケーションで、正確にはどのように機能するのか見てみましょう。
- Sidekiqプロセスをデフォルト設定の25スレッドで実行しているとします。
- Sidekiqは5つの新しいジョブの実行を開始します。 外部のクレジット・カード・プロセッサと通信します...HTTPS経由でリクエストをPOSTし、〜3秒後にレスポンスを受け取ります。
- 各ジョブ(Rubylandでは別々のスレッドを実行しています)はHTTPリクエストを送信し、IOモジュールを使ってレスポンスを待ちます。 一般的には、CRubyのほとんど全てのIOは、グローバルVMロックを解放します。スレッドは並行して動作しており、メインメモリ領域のロックを争う可能性があります。これが新しいメモリアリーナを作成する理由になります。
複数のCRubyスレッドが実行されていても、I/Oが実行されていない場合、グローバルVMロックは2つのRubyスレッドが同時にRubyコードを実行することを妨げるので、メインメモリ領域を争うことはほとんどありえません。 したがって、スレッド・メモリごとのアリーナは、マルチ・スレッドでかつI/Oを実行するCRubyアプリケーションにのみに影響します。
これがどのようにメモリの断片化につながるのでしょうか?
 ビン・パッキングも楽しくなります!
ビン・パッキングも楽しくなります!
メモリの断片化は本質的には(訳注:数学での)ビン・パッキング問題です...いかに効率的に、サイズの違うアイテムを、なるべく隙間が少なくなくなるように複数の箱に分配するか?という問題です。ビン・パッキングはアロケーターにとってもっと難しい問題になります。理由としてはa)Rubyは決してメモリ領域を動かしません(一度領域をアロケートすると、解放されるまで、オブジェクト/データはその場所を占有し続けます)。b)スレッドごとのメモリアリーナは基本的に多数の異なる箱(ビン-bin)を作成します。つなげたり、"ひとまとめ"にすることはできません。ビン・パッキングはすでにNP困難で、これらの制約で理想的な解決策を適用するのが、より困難になっています。
時間の経過とともに大量の RSS の使用につながるスレッドごとのメモリのアリーナは、libcのmallocトラッカーの問題に類するものとして知られています。実はMallocInternals wikiで、下のように具体的に説明されています:
スレッドの衝突からの圧力が増加するにつれ、圧力を緩和するために、追加アリーナがmmap経由で作成されます。アリーナの数はシステム中のCPUの数の8倍までに制限されます(ユーザが別の指定をしていない限り。melloptを参照のこと)。これは、スレッドを大量に使用するアプリケーションでは、まだ競合あることを意味します。しかし、トレード・オフとして断片化は少なくなるでしょう。
お分かりになったでしょう...利用可能なメモリ・アリーナを少なくすると、断片化が減少します。明らかなトレード・オフがここにはあります。:アリーナを少なくすると、メモリ使用量が減少します。しかしプログラムはロックの競合が増えるため遅くなります。
HEROKUはCedar-14スタックを開発した時、glbicをバージョン2.19にアップグレードしたため、スレッドごとのメモリ・アリーナの副作用に気づきました。
HEROKUの顧客は、アプリケーションを新しいスタックにアップグレードした時、メモリ使用量が大幅に増加するとレポートしました。HEROKUのテレンス・ホーン(Terrence Hone)がテストを行い、興味深い結果を得ました:
|
設定 |
メモリ使用量 |
|
ベース(arenaの制限なし) |
1.73倍 |
|
ベース(arena導入前) |
1倍 |
|
MALLOC_ARENA_MAX=1 |
0.86 |
|
MALLOC_ARENA_MAX=2 |
0.87 |
基本的にlibc2.19のメモリアリーナのデフォルトの動作では、実行時間が10%減少しています。しかしメモリの使用量は75%も増加しました!メモリ・アリーナを最大2つに減らすと、基本的にはスピードの増加分が相殺されます。しかし旧Cedar-10スタックではメモリ使用量が10%減少しました(そして、デフォルトのメモリ・アリーナの動作と比較して、メモリ使用量を約2倍削減しました!)。
|
設定 |
レスポンス・タイム |
|
ベース(arenaの制限なし) |
0.9倍 |
|
ベース(arena導入前) |
1倍 |
|
MALLOC_ARENA_MAX=1 |
1.15倍 |
|
MALLOC_ARENA_MAX=2 |
1.03倍 |
ほぼ全てのRubyアプリケーションで、75%のメモリ使用量の増加と10%のスピードの増加は適切なトレード・オフではありません。しかし、もう少しだけ現実的な事例を見てみましょう。
再現性の問題
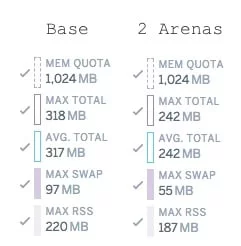
ランダムなデータを作成して、レスポンスをデータベースへ書き込むSidekiqジョブのデモ・アプリケーションを作成しました。
MALLOC_ARENA_MAXを2に変更した後でも、メモリ使用量は24時間後に15%だけ少ないだけでした。
私は現実世界のワーク・ロードは、この現象を大幅な拡大することに気がつきました。私はまだ、断片化をもたらすアロケーション・パターンについて、全ては理解していないということでしょう。Railsパフォーマンス完全ガイドのSlackチャンネルで、私はMALLOC_ARENA_MAX=2に設定された製品が、2、3倍のメモリ削減を示すメモリ・グラフを多く見てきました。
問題の解決
この問題には2つの主要な解決策があります。関連して、将来もう一つ解決策が提供されるかもしれません。
解決策1: メモリ・アリーナを削減する
利用できるメモリアリーナの最大数を削減すことはかなり有望な解決策です。MALLOC_ARENA_MAX 環境変数を変更することによって行えます。前述のように、アロケーターでのロックの競合が増加し、広範囲に渡ってアプリケーションのパフォーマンスに悪影響を与えます。
ここで、一般的に推奨できる設定をあげることは不可能ですが、ほとんどの Ruby アプリケーションには2~4のアリーナが適しているようです。MALLOC_ARENA_MAXを1に設定すると、ほんのわずかのメモリ使用量の改善(1~2%)と引き換えに、パフォーマンスに大きな悪影響があるようです。
メモリ使用量の減少とパフォーマンスの減少、両方の結果を測定しながら、アプリケーションにとって適切なトレードオフになるまで、様々な設定を試します。
解決策2:jemallocを使用する
NateのTwitter:https://twitter.com/nateberkopec/status/936627901071466496
(jemallocを使用した時と使用しない時を比較した、CodeTriageのSidekiqワーカーのメモリ使用量です。いったいどのくらいの数のRubyのメモリの問題が、アロケーターのみによって引き起こされているのかと、本気で考え始めました。)
もう一つの解決策は、単に別のアロケーターーを使用することです。jemallocもスレッドごとのアリーナを実装していますが、その設計はmallocにある断片化の問題を回避しているようです。
上のツイートは、CodeTriageのバックグラウンド・ジョブ・プロセスからjemalloc を削除した時のものです。ご覧の通り、効果はかなり劇的でした。またMALLOC_ARENA_MAX=2でmallocを使用して実験しましたが、jemallocの約4倍のメモリ使用量になりました。Rubyでjemallocに切り替えることが可能な場合は、そうしてください。はるかに少ないメモリ使用量でmallocと同じか、良いパフォーマンスになるようです。
このブログ記事はjemallocのためのものではありませんが、Rubyでjemallocを使用するにあたり、より詳細なポイントをいくつかあげておきます:
- このビルド・パックのHEROKUではjemallocで使用できます。
- Rubyではjemalloc 4.xを使用しないでください。Transparent Huge Page(THP)と悪い相互作用があり、期待されるメモリ削減量が減少します。代わりにjemalloc 3.6を使用して下さい。5.0のRubyでのパフォーマンスは現在わかっていません。
- jemallocでRubyをコンパイルする必要はありません(できるはずですが)。 LD_PRELOADでダイナミック・ロードができます。
解決策3:コンパクティングGC(Compacting GC)
断片化は一般的に、メモリ領域を動かせる場合削減できます。CRubyでは、C拡張機能がRubyのメモリを参照するためにrawポインタを使用する可能性があります...メモリ領域の移動は、セグメンテーション違反もしくは不正なデータが読み取られる原因になるでしょう。
アーロン・パターソン(Aaron Patterson)は現在、コンパクティング・ガベージ・コレクタを開発しています。有望に見えますが、おそらくまだ時間がかかるでしょう。
蛇足
マルチ・スレッドのRubyプログラムは、mallocにおいてスレッドごとのメモリ・アリーナが引き起こすメモリ断片化のために、本来の必要量の2~4倍のメモリを消費します。解決するためにはMALLOC_ARENA_MAX環境変数でアリーナの最大数を少なくするか、jemallocのようなパフォーマンスがより良好な別のアロケーターに切り替えることができます。
潜在的なメモリの削減の効果は本当に素晴らしく、ペナルティーはごくわずかです。RubyでPumaかSidekiqを使用する製品には、いつもJemallocを使用することをお勧めします。
効果はCRubyで最も顕著な一方で、JVMとJRubyにも影響するでしょう。
ウェブ・サイトを高速化したいですか?
私はネイト・ベルコペック (@nateberkopec)です。 フル・スタック・エンジニアの観点から、ウェブのパフォーマンス、主にフロント・エンドとRubyのバック・エンドについて、オンライン記事を書いています。 もし、この記事が気に入って、次の記事について知りたい場合は、連絡をください。 毎週1通程度、Eメールを私から直接送ります。スパムではありません。控えめです。
Railsパフォーマンス完全ガイド

私が書いた「Railsパフォーマンス完全ガイド」を見てください! Ruby on Railsアプリケーションをより速く、よりスケーラブルに、より簡単にメンテナンスするためのツールを提供する、フル・スタックコースです。 361ページのPDF、プライベートSlack、15時間以上のビデオ・コンテンツが含まれています。




