Rubyアプリケーションを毎分1000リクエストにスケールさせる: 初心者ガイド
ネイト・ベルコペック (@nateberkopec) SpeedShop(詳細),Railsパフォーマンス・コンサルタンシー
要約:Rubyアプリケーションのための”スケーリング”についての情報は、毎秒数百リクエストを処理している企業によって書かれたものがほとんどです。そうではない私たちのためのスケーリングはどのようなものでしょうか?
スケーリングは敷居の高いトピックです。Rubyアプリケーションのスケーリングに関するブログやインターネットでの情報のほとんどは、毎分何万ものリクエストへのスケーリングについて書かれたものです。TwitterやShopifyの規模です。興味深いですが...Rubyでどれくらいできるか、上限を知ることはいいことです...1台よりは多いものの、せいぜい100台以下のサーバでアプリケーションを実行している、私たちのような大多数にとってはあまり役に立ちません。スケーリングのための”初心者ガイド”はないのでしょうか。(*1)
*1 ほとんどの人にとって、自分がどれくらいの大きさなのかは、自分が本当に大きくなるまでは、表明しづらいためだと思います。
Rubyアプリケーション開発者のための、スケーリングに関するほとんどの情報は、このように、まったくニーズに当てはまらないものです。Twitterが使った毎秒10リクエストを毎秒600リクエストにスケールするテクニックは、あなたのアプリケーションを毎分10リクエストから、毎分1000リクエストにするには、適当ではないでしょう。メガ・スケールには一連の固有の問題があります。...特にデータ・ベースI/Oが問題になります。アプリケーションは水平に(プロセスと、マシンにわたって)スケールさせることが多いですが、データ・ベースは垂直に(CPUとRAMを追加することによって)スケールします。これらすべての関係のために、スケーリングは、ほとんどのRailsアプリケーション開発者にとって、難しいトピックになっています。どんな時にスケール・アップしますか?そしてどんな時にスケール・ダウンしますか?
 (字幕:じゃああんまり関係ないんじゃない?)
(字幕:じゃああんまり関係ないんじゃない?)
これは私のことです。どのように毎秒1000リクエストのアプリケーションがスケールされているか、という記事を読んだ後、私のアプリケーションは毎分10リクエストしか受け取っていません。
議論を1000RPM(Requests Per Minute、1分毎のリクエスト数)かそれ以下に絞りたいと考えているため、以下に議論しない事をあげておきます:データ・ベースやMemcache、Redisなどの他のデータ・ストア、RabbitMQやKafkaなどのハイ・パフォーマンス・メッセージ・キューの使用、分散オブジェクト。またこの記事では、スケーリングの役に立つとは思いますが、どのようにして早い応答時間を得るかは話しません。
デブオプス(devops)やアプリケーション・サーバー(Unicorn, Puma,など)関連についても何も触れません。第一に、心苦しいのですが、私のプロフェッショナルとしてのキャリアは、主にHEROKUプラットフォームでのアプリケーション開発でした(*2)。単純にHEROKU以外のプラットフォームでスケーリングするための、カスタム・セットアップ (Docker, Chef, what-have-you) について、お話しできる経験がないのです。第二に、毎分1000リクエスト以下の運営をしている場合、あなたのデブオプス・ワーク・フローはそれほど変える必要はないでしょう。デブオプスの状況にかかわらず、この記事で得られるすべての情報は、どんなRubyアプリケーションにも適用できるはずです。
*2 私は毎分1000リクエスト以下のシステム規模の、小さいスタートアップ企業での仕事をしています。 ほとんどの場合、あなたは唯一の開発者、または一握りの開発者です。 このような小規模のシステムを扱う小さなチームにとって、HEROKUの恩恵は計り知れません。開発者はChef / Ansible / Docker / DevOps Flavor Of the Weekに煩わされずに済むので、時間を大きく節約できます。 はい。サーバーの請求書にある金額の50%増しを、確かに払うことになるかもしれませんが。
コンサルタントとして、いままで多くのRailsアプリケーションを見てきました。ほとんどがスケールし過ぎていて、お金を無駄にしていました。
HEROKUのdynoスライダーと、AWSの多くのサービスが、スケーリングを簡単にしてくれます。しかし、必要のない時でもスケールを簡単にしてくれるのです。Rails開発者の多くは、dynoをスケールするか、インスタンス・サイズを大きくすれば、アプリケーションが速くなると思っています(*3)。アプリケーションが遅い時の、最初の反応は、dynoをスケールするか、インスタンス・サイズを大きくすることです。(本当に...HEROKUのサポートは、通常そう勧めます!お金をもっと払えば、問題が解決すると言うのです!)にもかかわらず、大抵の場合は問題解決の助けになりません。サイトは遅いままです。
*3はい。HEROKUでdynoのスケーリングを使用しても、アプリケーションがリクエスト・キューを持っていて、リクエストがそのキューの中で、処理が開始されるのを待っている、という状況が常に起こっていない限り、アプリケーションが高速になることは決してありません(後述)。 PX dynoでさえも、パフォーマンスがより安定するだけで速くはなりません。 ただし、AWSでインスタンス・タイプを変更すると(例えばT2からM4)、アプリケーション・インスタンスのパフォーマンス特性が変わるかもしれません。
この記事の用語として:ホストとは、仮想化された、もしくは物理的なシングル・ホスト・マシンを指します。 HEROKUではdynoです。 サーバーと呼ぶ人もいるかもしれませんが、この記事のために、ホスト・マシンとそのマシン上で実行される、アプリケーション・サーバを区別したいのです。UnicornやPumaなどでは、シングル・ホストで多くのアプリケーション・サーバを実行できます。 HEROKUでは、一つのホストが一つのアプリケーション・サーバーを実行します。アプリケーション・サーバには多数のアプリケーション・インスタンスがあり、それらは別々の"ワーカー"プロセス(Unicornなど)またはスレッド(マルチ・スレッドでJRubyを実行している場合はPuma)になります。
この記事での定義に照らせば、MRI上(Pumaなど)のシングル・アプリケーション・インスタンスとスレッド・webサーバは、アプリケーション・インスタンスではありません。同時には一つのスレッドしか実行されないためです。したがって、一般的なHerokuの設定では、シングル・ホスト/dynoに、一つのアプリケーション・サーバー(一つのPumaマスター・プロセス)と3〜4つのアプリケーション・インスタンス(Pumaクラスタ・ワーカ)があるということになるでしょう。
スケーリングによって改善するのは速度ではなくスループットです。 ホストのスケーリングは、処理開始を待っているリクエストがある場合にのみ応答時間を短縮します。 処理開始を待っているリクエストがない場合、スケーリングはお金を無駄にするだけです。
1分毎に1リクエストから1分毎に1000リクエストに、Rubyアプリケーションを正しくスケールする方法について学ぶには、アプリケーション・サーバーとHTTPルーティングが、実際にどのように働くかについて、かなりの量を学ぶ必要があるでしょう。
私は例としてHEROKUを使いますが、多くのカスタム・デブオプスの設定においてもほとんど同じように動作します。 これまで実際に、"ルーティング・メッシュ"とは、もしくはサーバーにルーティングされる前に、リクエストがどこでキューに入れられるか、考えたことがありますか? そうです、今から明らかになります。
どのようにリクエストはアプリケーション・サーバーにルーティングされるか
Ruby Webアプリケーションをスケールする時に、あなたができる最も重要な選択の1つは、どのアプリケーション・サーバを選ぶかです。Rubyアプリケーション・サーバの世界は過去5年間で劇的に変化しました。その劇的な変化の大半は去年起こっています(訳注:この記事の執筆は2015/07/29)。しかし、各アプリケーション・サーバーを選択するために、長所と短所を理解するには、まず最初に、リクエストがアプリケーション・サーバにルーティングされる方法についても学ぶ必要があります。
当然、多くの開発者は、リクエストがどのようにルーティングされ、キューに入れられるかを理解していません。 簡単ではありません。 下記は、Rails開発者の多くが今のところHEROKUについて理解していることのまとめです。
 ええと、ルーターはUnnicornをバランスするの?それともPumaを?
ええと、ルーターはUnnicornをバランスするの?それともPumaを?
"ルーティングはBambooとCedarスタックの間で変わると思う。"
“RapGeniusはずっと前から問題ないって?問題あったと思うよ。だってリクエストのキューイングが間違ってリポートされていたもの。”
”Unicornを使わなければ、あれ、ちょっとまって、HEROKUが今はPumaを使うべきだと言っているみたい。なんでだろう。”
“どこにあるのかはよくわかりませんが、どこかにリクエストキューがあります。”
HTTPルーティングにおけるHEROKUのドキュメントを、最初に読むことは良いことですが、全体像を完全に説明するものではありません。例えば、HEROKUがアプリケーション・サーバとしてUnicornかPumaを推奨する理由はすぐにはわかりません。また、リクエストが「キューに入れられる」場所や、どのキューが最も重要であるかについても、実際にはドキュメントに記載されていません。ですので、リクエストの最初から最後まで見てみましょう!
リクエストのライフ・サイクル
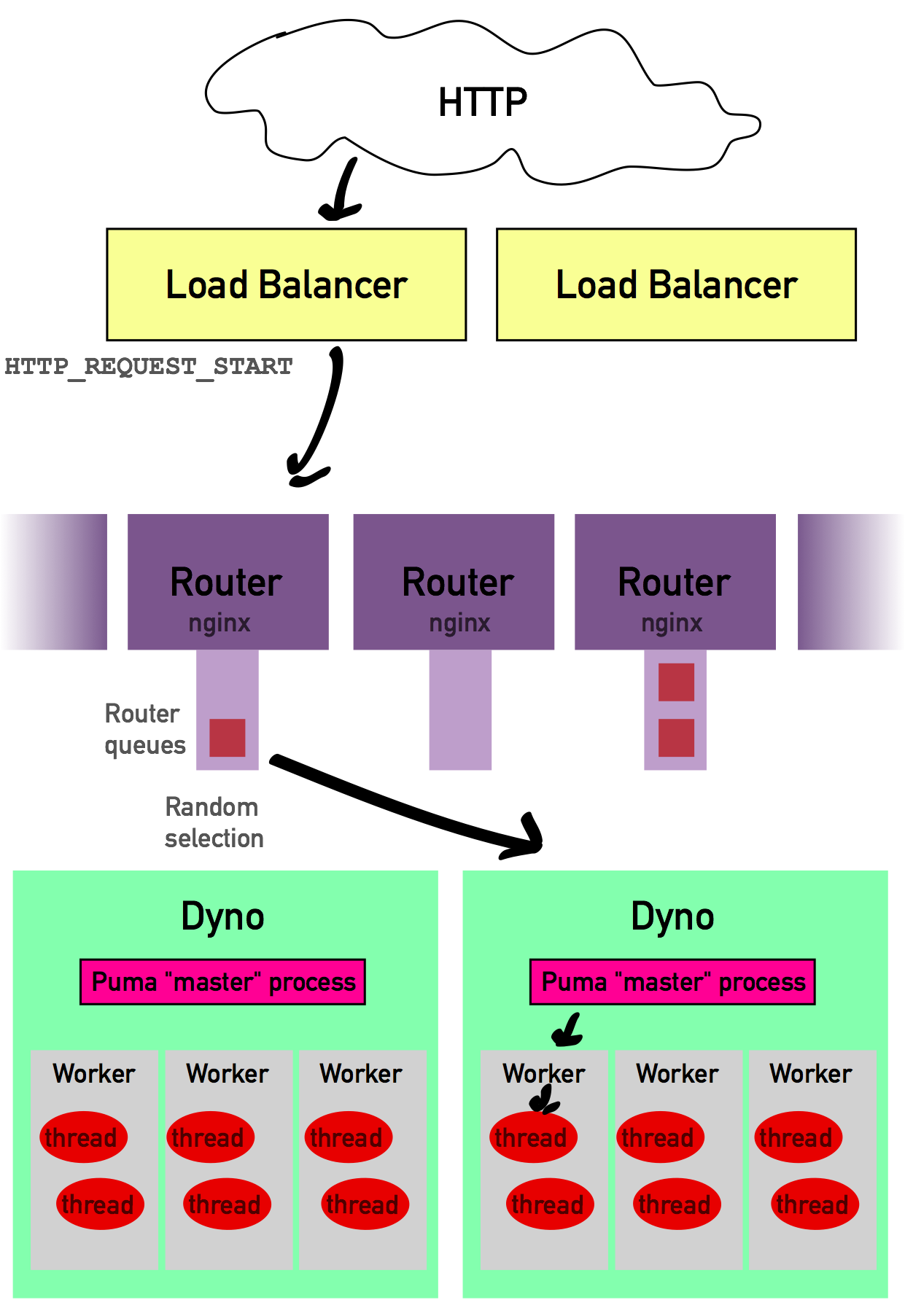
リクエストがyourapp.herokuapp.comに届いた時、最初に通過する場所はロードバランサです。ロード・バランサの仕事は、Herokuのルータ間の負荷が均等に分散されるようにすることです...そのため、どのルータにリクエストを送るべきかを決める以外は、たいしたことをしていません。ロード・バランサは、リクエストを最適と考えられるルータにに引き渡します。(HEROKUは、ロード・バランサがどのように機能するのか、またどのようにしてルータを選択するのか、公式には説明していません)
これで、HEROKUルータに到着しました。 HEROKUルータの数は明らかにされていませんが、少なくともかなり多い(100以上?)と想定できます。ルータの仕事は、あなたのアプリケーションのdynoを見つけて、リクエストを渡すことです。そして、1〜5msほど時間をかけてあなたのdynoを見つけた後、アプリケーションが実行されているdynoの一つにランダムに接続しようとします。はい。ランダムです。 これが数年前に、RapGeniusが誤解を受けたところです(当時、HEROKUは、ルータがどのdynoを選択してルーティングするかについて、最悪にわかりづらく、誤解を招きやすいものでした)。HEROKUがランダムにdynoを選択すると、dynoがリクエストを受け入れて接続を開くまで最大5秒間待機します。リクエストが接続を待っている間、ルータのリクエスト・キューに入っています。ただし、各ルーターにはそれぞれ独自にリクエスト・キューがあります。HEROKUはルーターの数がいくつか公開していませんが、おそらくあなたのアプリケーションに、いつでも大量のルータ・キューがあるはずです。HEROKUは、リクエスト・キューに入れられたリクエストの数が大きくなりすぎると、リクエストをリクエスト・キューから破棄し始めるでしょう。また、応答していないdynoを隔離しようとします。(ただし、これもルータ単位で個別に行われるため、Herokuの各ルーターはそれぞれ不具合のあるdynoを隔離する必要があります)(*4)
*4ここに書かれている説明は、基本的に、ほとんどのカスタム・セットアップにおけるnginxの利用にも当てはまります。DigitalOceanチュートリアルを参照してください。これらの設定では、nginxがロード・バランサとリバース・プロキシの両方の役割を果たすことがあります。よりアグレッシブな設定を選択したいかもしれませんが、チュートリアルにある全ての挙動はnginxのカスタム・セットアップを利用してコピーできます。Nginxはアップ・ストリームのアプリケーション・サーバーが稼働しているかどうかを確認するために、実際にはヘルス・チェック要求を頻繁に送信しています。ただし、nginxのカスタム・セットアップは独自のリクエスト・キューを持たないことが多いです。
HEROKUユーザーにとって重要な2つの項目があります。ルータは、dynoへの接続が成功するまで最大5秒間待機し、待機している間、他のリクエストはルーターのリクエスト・キューで待機します。
サーバに接続する。サーバ選択の重要性
ルータ(*5)がサーバーに接続を試みるステージは、スケーリングを理解するために最も重要です。何が起こるかはWebサーバの選択によって大きく異なります。選択に応じて、次のようになります。
*5カスタム・セットアップを使用している人へ、私がルータと言っているものは、皆さんが”nginx”または”Apache”と言っているものです。
Webrick (Railsのデフォルト)
Webrickはシングル・スレッド、シングル・プロセスのWebサーバです。
ルータからリクエストを全て受け取るまでルータへの接続を開いたままにします。 ルータはそれから次のリクエストに進むでしょう。Webrickサーバはそのリクエストを引き受け、あなたのアプリケーション・コードを実行し、ルータにレスポンスを送り返します。 この間ずっと、ホストはビジー状態で他のルータからの接続を受け付けません。要求の処理中にルータがこのホストに接続しようとすると、ルーターはホストの準備ができるまで(HEROKUでは最大5秒)待機します。待機している間、ルータは他のdynoに対して別の接続を試みることはありません。Webrickの問題は、リクエストやアップロードが遅いことだと大げさに言われています。
誰かが自分の猫の4K HDビデオを、56Kモデムを介してアップロードしようとしているなら不運です。Webrickは待機して、リクエストされた処理を待っている間、何もしません。3Gの携帯電話を使っているモバイル・ユーザーが来ましたか?最悪です。Webrickは待機して、痛い痛しいまでに時間がかかるそのユーザのリクエストが完了するのを待っています。
Webrickは遅いクライアント・リクエストや遅いアプリケーション・レスポンスにうまく対応できません。
Thin
Thinは、イベント駆動型のシングル・プロセスWebサーバです。(*7)
*7 シングルホスト上で複数のThingsを実行する方法があります...ただし、Unicornのような一つのソケット上ではなく、それぞれ異なるソケット上で待機しなければなりません。 これにより、HEROKUの設定と互換性がなくなります。
ThinはEventMachineを内部で使用しています(このプロセスはイベント駆動型I/O(evented I/O)と呼ばれることもあります。Node.jsように機能するわけではありません)。理論的にはいくつか利点があります。
Thinはルータとの接続を開き、要求の一部を受け入れ始めます。 ただし、ここに工夫があります。突然リクエストが遅くなったり、データがソケットを介して受信されなくなった場合、ThinはOffになり他のことをします。これはThinを低速クライアントからの保護していることをさします。クライアントの速度がいくら遅くても、その間に、ThinがOffになり他のルーターから他の接続を受け入れることができるためです。リクエストを完全に受け取った時にのみ、Thinはリクエストをアプリケーションに渡します。 実際、Thinは非常に大きな要求(アップロードなど)をディスク上の一時ファイルに書き込んだりもします。
Thinはマルチ・プロセスではなくマルチ・スレッドで、スレッドはMRI上で同時に一つしか実行されません。そのため、実際にアプリケーションを実行している間は、ホストは使用できなくなります(上記のWebrickのセクションで概説した全てのネガティブな事柄によるものです)。EventMachineにとても詳しいのなら別ですが、Thinもアプリケーション・コード内のI/Oが終了するのを待っている間、他のリクエストを受け入れることができません。例えば、アプリケーション・コードが、クレジットカードの決済を行うために、課金サービスにPOSTを発行した場合、Thinはデフォルトでは、そのI/O操作が完了するのを待っている間、新しい要求を受け入れることができません。基本的にはThiに、"処理が終わるのを待っているのなら、他の処理をしよろ"と伝えるために、EventMachineのReactorループにイベントを送り返すように、アプリケーション・コードを変更する必要があります。どのように機能するかについての詳細は、ここにあります。
Thinは、遅いクライアントのリクエストに対処できますが、カスタム・コーディングを本当に多く行わないと、遅いアプリケーション応答やアプリケーションI/Oに対処できません。
Unicorn
Unicornはシングル・スレッド、マルチ・プロセスのwebサーバーです。
Unicornはいくつか”ワーカ・プロセス”(アプリケーション・インスタンス)を作成します。これらのプロセスは全て待機し、”マスタ・プロセス”がコーディネートしている、一つのUnixソケットをリッスン(listen-待ち受け)しています。ホストから接続リクエストが来ると、マスタ・プロセスへではなく、Unicornソケットへ渡されます。そこでは、全てのワーカ・プロセスが待機しており、リッスンしています。これがUnicom独自の実装です...”マスタ・プロセス”のインターフェースなしに、”ワーカ・プール”の一種として、Unixのドメイン・ソケットを使うRubyサーバは(私の知っている限りでは)他にありません。(処理するリクエストがないため、ソケットをリッスンしているだけの)ワーカープロセスはソケットからのリクエストをアクセプト(accept-受け入れ)します。ソケット上で、リクエストを全て受け取るまで(遅いクライアントだったら?)待ちます。そしてリクエストを処理するために、リッスンするのをやめます。その後リクエストの処理が終わるとレスポンスを送信し、ソケットをリッスンする状態に戻ります。
Webrickと同じ理由で、Unicornは遅いクライアントに対して脆弱です(*8)。ソケットからリクエストを受け取っている間、Unicornワーカは新しいコネクションをアクセプトできません。そのためワーカは使用できなくなります。基本的に、Unicornワーカーと同じ数の遅いリクエストにしか対応できません。Unicornワーカが3つあり、受け取るまで1000m秒かかる遅いリクエストが4つある時、4番目のリクエストは待機して、他のリクエストが処理されるのを待たなければなりません。この手法は、しばしばマルチ・プロセス・ブロッキングI/Oと呼ばれます。この方法では、Unicornは遅いアプリケーション応答には対応できます。(まだ空いているワーカが、他のワーカが処理している間、接続をアクセプトできるためです)しかし、遅いクライアントのリクエストには(あまり)対応できません。Unicornのソケット・ベースの仕組みは、インテリジェント・ルーティングと同じ形をしていることに気付きがます。利用可能なアプリケーション・インスタンスだけが、ソケットからリクエストをアクセプトするからです。
*8 ngixのカスタム設定でUnicornへのリクエストをバッファし、遅いクライアントの問題を除去することができます。これは正にPassengerが行っていることです。あとで解説します。
Phusion Passenger 5
PassengerはハイブリッドなI/Oモデルを使います。Unicornのようにマルチ・プロセス、ワーカ・ベースの構成をとります。しかしリバース・プロキシ(reverse proxy - 逆プロキシ)のバッファリングを含んでいます。
これは重要です。nginxをアプリケーション・ワーカの前で動作させることに少し似ています。加えて、もしPassenger Enterpriseに料金を払うと、(後で説明するPumaのように)それぞれのワーカ上で、複数のアプリケーション・スレッドを動作させることができます。Phusion Passenger 5に組み込まれたリバース・プロキシ(Rubyではなくて、C++で書かれている、カスタマイズされたnginxインスタンスです)が重要な理由を知るために、Passengerへのリクエストを通してみてみましょう。ソケットの代わりに、HEROKUのルーターはngixに直接接続し、リクエストを渡します。nginxは特別に最適化されたものです。Rubyのwebアプリケーションへの務めを極めて効率的にする、多くの素晴らしいテクニックが全面的に使われています。次の段階に渡す前に、リクエストを全て受け取ります...ワーカを遅いアップロードや、他の遅いクライアントから守ってくれます。
リクエストの受け取りが完了すると、nginxはリクエストをHelperAgentプロセスに渡します。HelperAgentが、リクエストをどのワーカが処理するべきかを決定します。Passenger 5は遅いアプリケーション・リスポンス(HelperAgentが使用されていないワーカ・プロセスにリクエストを渡すため)と遅いクライアント(nginx独自のインスタンスが使用され、クライアントがバッファされるため)を扱うことができます。
Puma (スレッド・モード)
デフォルト・モードで起動されたPumaはマルチ・スレッドで、シングルプロセスのサーバです。アプリケーションが、ホストに接続する時、EventMachine風のReactorスレッドに接続します。このスレッドは、リクエストの受け取りを担当し、遅いクライアントのリクエストを非同期に待ちうけ、次の段階に一度に送ります(Thinのように。念のため)。リクエストの受け取りが完了すると、Reactorスレッドは、アプリケーションと通信をする新しいスレッドを生成します。そしてこのスレッドがリクエストを処理します。同時に実行されているアプリケーション・スレッド数の最大値を設定できます。重ねて述べますが、この設定では、Pumaはマルチ・プロセスではなく、マルチ・スレッドです。MRI Ruby上で、同時に一つのスレッドしか動作しません。Thinと違い、しかし何がPumaの特色かと言うと、スレッドを活用するために、アプリケーション・コードを変更する必要がないということです。アプリケーション・スレッドがI/Oを待つ時、Pumaは自動的にプロセスに制御を戻します。例えばもし、アプリケーションが課金プロバイダーからのHTTPレスポンスを待っている時、PumaはReactorスレッドでリクエストをアクセプトできます。異なるアプリケーションスレッドの中にある他のリクエストですら実行します。そのため、I/Oオペレーションを待っている間(データーベースやネットワーク・リクエストなど)や、アプリケーションが実行されている間、ホストが利用できなくなるという上記のWebrickのセクションで概説したようなすべての問題に対して、Pumaはより高いパフォーマンスを提供することができます。Puma(スレッドのみのモード)は遅いクライアントに対処できます。しかしアプリケーションのCPUに起因する遅いレスポンスには対応できません。
Puma (クラスタ化)
Pumaにはマルチ・スレッド・モデルとunicornのマルチ・プロセス・モデルを組わせた、”クラスタ”モードがあります。
クラスタモードでは、HEROKUのルータはPumaの"マスタ・プロセス"に接続します。基本的には単に上記のPumaの例で説明したReactorの部分です。マスタ・プロセスの Reactorは送られてくるリクエストを受け取りバッファします。そして(Unicornと同様)Unixソケット上で待機している、任意の使用可能なPumaワーカに渡します。クラスタモードでは、そのため、(リクエストを受け取り、渡すという役割をこなすマスタ・プロセスのおかげで)Pumaは遅いリクエストに対処でき、(複数ワーカを生成しているおかげで)遅いアプリケーションのレスポンスにも対応できます。
これら全ては何を意味するのでしょうか?
さて、もしずっと注意を払って読んできたのであれば、Rubyのスケーラブルなwebアプリケーションには、リクエストのバッファリングによる、遅いクライアントの対策、そして、並行度を高める...マルチ・スレッドかマルチ・プロセス/フォーク(できれば両方)による、遅いレスポンスの対策が必要だということをご理解いただけたでしょう。この条件に当てはめると、PumaのクラスタモードかPhusion Passenger 5が、MRI/C Rubyを実行しているHEROKU上で、Rubyアプリケーションをスケールするためのソリューションとして残ります。もし独自の環境で運営しているのであれば、Unicornとnginxが現実的な選択になるでしょう。
これらのwebサーバはそれぞれ”スピード”について様々な説明をしていますが、私はあまり参考にしていません。毎分1000リクエストは全てのwebサーバが扱えます。実際にはリクエストを処理するのに1ミリ秒もかかりません。 もしPumaがUnicornより0.001ミリ秒早いとしたら、たしかにすごいことですが、しかし、もしRailsアプリケーションがリクエストにこたえるのに100ミリ秒かかっているとしたら、あまり助けにならないでしょう。一番の違いはRubyのアプリケーション・サーバーのスピードではなく、異なるI/Oモデルとその特徴なのです。上で議論したように、まじめに考えれば、PumaのクラスタモードとPhusion Passenger 5だけが、Rubyアプリケーションをスケールするための選択だと私は考えています。I/Oモデルが遅いクライアントと遅いアプリケーションをうまく扱えるからです。他にも異なる機能が多くあります、PhusionはPassengerに大企業向けのサポートを提供しています。ですの、どれが最も良いか、機能を全て自分で比較してください。
“キュー・タイム”とは何の意味でしょうか?
上の説明で見てきたように、"リクエスト・キュー"は一つだけではありません。実際、アプリケーションは何百もの"リクエスト・キュー"と関わっています。以下にリクエストが"キュー"される場所を全てあげます。
■ロード・バランサ。あまり起きないでしょう。ロード・バランサはとても早くなるように調整されています。(~10ロード・バランサ・キュー?)
■100以上のHEROKUルータ。各ルータは独立したキューを持っています。(100以上のルータ・キュー)
■もしUnicorn,PumaそしてPhusion Passengerのようなマルチ・プロセスサーバを使用しているのなら、"マスタ・プロセス"もしくはホストの中でキューされています。(ホストごとに1キュー)
New Relicはキュー・タイムのレポートを、いったいどのような方法でおこなっているのでしょうか。
そうです、これがRapGeniusが炎上した理由です。2013年、RapGeniusは炎上しました。HEROKUの"インテリジェント・ルーティング"が全くインテリジェント(賢く)でないことが発見されたのです...事実、完全にランダムでした(*9)。
*9インテリジェント・ルーティングは、我々にとってはせいぜい何かランダムよりは良いぐらいの意味でしかありませんが、通常インテリジェント・ルーティングはアップ・ストリームのアプリケーション・サーバにpingを送り続けて、新規にリクエストをアクセプトする準備ができているか調べます。ルータの待ち時間が減ります。
さらに悪いことには、HEROKUのインフラは、まるでインテリジェント・ルータがあるようにステータスをリポートしていました(ルータごとの一つのキューではなく、一つのリクエストキュー)。HEROKUはNew Relicに(HTTPヘッダの形で)キュー・タイムのレポートを返します。これをNew Relicは”合計キュー・タイム”として表示していました。しかし、このヘッダは、ルータ・キューの中で、ある特定のリクエストが留まった時間をレポートしていました。ホストの負荷にかかわらず、100もルータがあれば、極めて低い値になり得ます!(*10)
*10想像してください...HEROKUがUnicornのマスタ・ソケットに接続して、リクエストをソケットに渡します。いまリクエストが500ミリ秒ソケット上でワーカが拾うまで待機したとすると、以前はルータ・キューの時間しかレポートされていなかったので、500ミリ秒に気づくことができませんでした。
最近はNew RelicはHEROKUのREQUEST_STARTコールのレポートに基づいて、キュー・タイムをレポートしています。このヘッダには、HEROKUがロードバランサでリクエストをアクセプトした時間が書かれています。New Relicはキュー・タイムを得るために、REQUEST_STARTからワーカがリクエスト処理を開始した時間を引いているだけです。したがって、もしREQUEST_STARTがちょうど12:00:00PMでアプリケーションが12:00:00.010まで処理を開始しなかったら、New Relicは10msをキュー・タイムとしてレポートします。全てのレベルでの時間経過が計算に入っているのは、なんと素晴らしいことなのでしょう:ロードバランサでの時間、HEROKUルータでの時間、そしてホストでキューイングに費やされた時間(Pumaのマスタ・プロセス、Unicornのワーカ・ソケット、その他)(*11)
*11もちろん、nginx/apacheインスタンスに正しいヘッダを設定すれば、正確なリクエストのキュー・タイムがあなたのカスタム・セットアップでも得られます。
いつアプリケーション・インスタンスをスケールするのでしょうか?
応答時間のみを判断材料にして、アプリケーションをスケールしないでください。リクエスト・キューに費やす時間が増えても、アプリケーションは遅くなるかもしれないし、そうではないかもしれません。リクエスト・キューが空なのに、ホストをスケールしようとすると、単なるお金の無駄になってしまいます。スケールするまえに、リクエスト・キューに費やされた時間を調べてください。
ワーカ・ホストについても同様です。ジョブ・キューの深さに応じて、スケールしてください。処理するのを待っているジョブがないのに、ワーカ・ホストをスケールするのは意味がありません。事実上ワーカdynoとウェブdynoは全く同じものです...どちらも処理が必要なジョブ(リクエスト)が入ってきます、処理を待っているジョブの数に応じて、スケールするべきです。
NewRelicはリクエスト・キューに費やされた時間を提供します。独自に計測するのに役に立つgemもありますが。もしリクエスト・キューにあまり時間がかかっていないなら(サーバーの平均応答時間中5-10ms以下であれば) 、スケールする意味は極めてわずかです。
Dynoの数はリトルの法則を満さなければなりません
開発者が毎秒どのくらいの数のリクエストをサーバーが処理できるのか理解していないため、アプリケーションがスケールし過ぎているのをよく見かけます。彼らには"毎分どのくらいのリクエスト数に、どのくらいのDynoが必要なのか?"という感覚がありません。
私はこの件に関して既に実用的な方法を説明しました。測定してリクエスト・キュー・タイムの変化に対応します。しかし、理論的な手段を使用する方法もあります...リトルの法則です。Wikipediaの説明は少し遠回りなので、ここに私が目的に合わせて作った式があります。
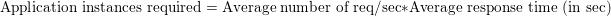
アプリケーション・インスタンスの数 = 毎秒の平均リクエスト数 * 平均応答時間(秒)
最初に、いくつか定義があります...上で触れているように、アプリケーション・インスタンスは環境での最小単位です。ジョブは1つの独立したリクエストを処理するためのもので、クライアントに返信されます。アプリケーション・インスタンスはWebrickプロセス全体です。MRIでPumaをスレッド・モードで使用している場合は、Pumaプロセス全体をアプリケーション・インスタンスとして定義します。JRubyを使用している場合は、それぞれのスレッドをアプリケーション・インスタンスとて数えます。Unicorn,Puma(クラスタモード)かPassengerを使っている時、アプリケーション・インスタンスは、それぞれの"ワーカ"・プロセスです(10)。
*10 本当のことを言えば、MRI上のマルチ・スレッドのPumaは、I/Oを待っている間も動作しているため、1.5アプリケーション・インスタンスとして数えるべきです。単純にするために、一つとしましょう。
典型的なRailsアプリケーションを数式に当てはめてみましょう...Unicornのプロトタイプのための環境です。例えば、Unicornプロセスがそれぞれ3つのunicornワーカを生成したとします。したがって、一つのサーバ・アプリケーションは、3つのアプリケーション・インスタンスを持っています。
もしアプリケーションが毎秒1リクエストを受け取っていて、平均応答時間が300ミリ秒だとします。負荷に対応するのに1*0.3=0.3アプリケーション・インスタンスしか必要としません。使用可能なサーバーの能力のうち、たった10%のしかここでは使っていないのです!アプリケーションの理論的な最大の能力はどのくらいなのでしょうか?未知数にして、少し式を変更してみます:
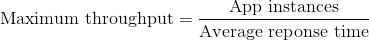
(最大スループット=アプリケーション・インスタンス数/平均応答時間)
さて、このアプリケーションの例では、最大スループットは3/0.3で、毎秒10リクエストです!けっこうすごいですね。
しかし理論は決して現実にならないものです。リトルの法則は結局は正しいのですが、広く分布し様々なサーバ応答時間の偏差(あるリクエストは0.1秒の処理時間で、他のリクエストは1秒の処理時間というように)もしくは、到着時間の広範囲な分布のために、残念ながら正確でなくなることもあります。しかし、オーバー・スケールしているかどうか、考えるためのよい”目安”になります(*11)。
*11 加えて、これらの注意事項がスケールにとってどんな意味を持つのか考えてください。リクエスト数の中央値がこの値に近い時だけ、実際のスループットを最大化することができます。応答時間が予想できるアプリケーションはスケーラブルです。もしサーバーの平均応答時間を使う代わりに、95パーセンタイルの応答時間を使用すれば、リトルの法則から実際もっと正確な結果を知ることができるでしょう。もしサーバの応答時間がわからず、予想できない時は、一番遅いレスポンスに注目しましょう。どうやって、95パーセンタイルの応答時間を減らせばよいのでしょうか。頑張ってSidekiq・DelayedJobなどのバック・グラウンド・プロセスを確認してみましょう。
もう一度確認しますが、ホストをスケールしても、直接にはサーバーの応答時間は減りません。リクエスト・キューを処理できるサーバ数が増えるだけです。もしキューの中で待っているリクエストの数が1より小さい時、サーバーは100%の能力を使っていないので、ホストをスケールするメリットは(100%そうとは言い切れないという意味で)ごくわずかです。最も効果があるのは、少なくとも1つのリクエストがキューの中に常にある時だけです。特に、サーバの応答時間が遅い時、この状況になる前にスケールをするのが良いこともあるかもしれません。しかし、スケールするにつれ、急速に改善が少なくなることに注意するべきです。
ですので、ホストの数を決める時はリトルの法則をつかって計算してください。リトルの法則をつかってホストをスケールするのは、最大能力まで25%かそれ以下しかない時だけです。その時、先を見通してスケールすると良いです。代わりの方法として、上で述べたように、NewRelicの計測で、リクエスト当たりのリクエスト・キューに費やされている時間が多い場合は、ホストをスケールすべきタイミングであることを示しており、良い指標になります。
数式でチェックする
2007年4月にSDフォーラム・シリコンバレーで、Twitterがどのようにスケールされているか、Twitterのエンジニアによるプレゼンテーションがありました。当時Twitterはまだ全てRailsアプリケーションでした。このプレゼンテーションで、エンジニアは次の数字をあげています。:
■毎秒600リクエスト
■180アプリケーション・インスタンス(mongrel)
■サーバ平均応答時間は約300ミリ秒
したがって、2007年、Twitterに必要な理論的なインスタンスは600*0.3、または180でした!そして、これと同じ数のインスタンスを実行していたようです。
能力を100% 最大使用することは、災害を招く様に設定することとほとんど同義です。Twitterは当時、本当に多くのスケーリングの問題を抱えていました。アプリケーション・インスタンスをスケールすることは出来ていないようでした。まだデータ・ベース・サーバ(やっぱりね)に捕らわれており、システムのいたるところには、インスタンスを増やしても解決でいないボトル・ネックがあったからです。
もう少し最近の例によると2013年に大規模Rubyを使ったShopifyのエンジニア、ジョン・ダフ(John Duff)がShopifyがどのようにRubyをスケールしているか(YouTube)を発表しました。このプレゼンテーションの中で(*12)、彼はこのように数字を公開しています:
*12 Railsをスケーリングに関するShopifyのプレゼンテーションはリトルの法則を使って書かれています。
■Shopifyは毎秒833リクエストを受け取る
■平均応答時間は72ミリ秒
■NginxとUnicornを使用し、53アプリケーション・サーバーで1172アプリケーション・インスタンス (!!!) を実行
さて、Shopifyに必要なインスタンス数は、理論的には833 * 0.072で~60アプリケーション・インスタンスです。でもなぜ彼らは1172使用していて、(理論的に)95%の能力を無駄にしているのでしょうか。もしアプリケーション・インスタンスが、リクエストを受け取るために、ソケットからデータを読むなど、何らか相互にブロックしているような場合、リトルの法則を保つことはできないでしょう。これが私が、MRI上のアプリケーション・インスタンスとして、Pumaスレッドを数えない理由です。他の理由として考えられるのはCPUかメモリの使用です...もしアプリケーション・サーバがCPUかメモリをフルに使用すると、全てのワーカは、能力をフルに使うことができなくなります。このアプリケーション・インスタンスのブロック(1172アプリケーション・インスタンスの同時実行を止める何か)があると、リトルの法則から大きな逸脱を招きます(*13)
*13 分布を持つリトルの法則の形があり、これら不正確なケースに約に立つかもしれません。しかし、数学の博士でない限り、おそらく理解することは難しいでしょう。
最後に2013年にEnvatoが投稿した、Railsのスケール方法について、いくつか数字を下に書きます:
■Envatoは毎秒115リクエストを受け取る
■平均応答時間147ミリ秒で実行
つまり数式は115*0.147で、Envatoは理論的に~17アプリケーション・インスタンスが負荷をまかなうために必要です。理論上の最大能力の37%で実行しているので、良い割合です。
チェックリスト:Rubyアプリケーションを1000RPMにスケールする5つのステップ
この記事が毎分1000リクエストにスケールするための良い手段になりますように。まとめとして、以下を覚えておいてください。
■遅いクライアントへの対策があり、ルーティング/プーリングが洗練されたマルチ・プロセスサーバを選択してください。Puma(クラスタモード)、フロントエンドngixのUnicorn、もしくはPhusion Passenger 5だけが選択肢です。
■dynoのスケーリングはスループットを向上させます。アプリケーションのスピードではありません。アプリケーションが遅いからといって、反射的に最初の手段としてスケーリングをするべきではありません。
■ホスト/dynoの数はリトルの法則に従わなければなりません。
■キュー・タイムは重要です。もしキュー・タイムが少ない時(<10ミリ秒)、ホストをスケールすることは意味がありません。
■3つのレバーがあることを念頭においてください...アプリケーション・インスタンスの数を増やす、応答時間を減らす、応答時間の変動を減らす。インスタンスがより少なくて済む、スケーラブルなアプリケーションは、応答時間が早く、変動が少ないです。
ウェブ・サイトを高速化したいですか?
私はネイト・ベルコペック (@nateberkopec)です。 フル・スタック・エンジニアの観点から、ウェブのパフォーマンス、主にフロント・エンドとRubyのバック・エンドについて、オンライン記事を書いています。 もし、この記事が気に入って、次の記事について知りたい場合は、連絡をください。 毎週1通程度、Eメールを私から直接送ります。スパムではありません。控えめです。
Railsパフォーマンス完全ガイド

私が書いた「Railsパフォーマンス完全ガイド」を見てください! Ruby on Railsアプリケーションをより速く、よりスケーラブルに、より簡単にメンテナンスするためのツールを提供する、フル・スタックコースです。 361ページのPDF、プライベートSlack、15時間以上のビデオ・コンテンツが含まれています。




