Serverless Architecture: Pros, Cons, and Examples
 Special contributor to Scout APM
on
March 10, 2022
Special contributor to Scout APM
on
March 10, 2022

Serverless Computing, or simply serverless, is a hot topic in the current software market. More and more companies are shifting their operations from traditional server-oriented architecture to faster, more modular serverless architecture. The “Big Three” cloud vendors (AWS, GCP, and Microsoft Azure) have shown immense interest in offering the best serverless experience possible. But what exactly is serverless? And how does it work if there is no server at all?
This article will look at serverless architecture and understand how it compares against the traditional server-oriented approach. We will also understand the architecture better with the help of some examples. We will bring our discussion to a close with a short list of use-cases where you can implement serverless without much deliberation. Feel free to navigate the guide using these links:
- What is Serverless Architecture?
- Serverless Architecture Examples
- Advantages of Using Serverless
- Potential Disadvantages of Using Serverless
- What’s Next for Serverless?
Without further ado, let’s begin!
What is Serverless Architecture?
Serverless is a cloud-native development model that enables software teams to build and deploy applications without directly managing servers and their requirements. While the architecture appears to function without a server, an underlying server is abstracted away from the application. The cloud provider handles the routine tasks of provisioning, maintaining, and scaling the server, while the user only pays for the execution time of their code on the machine.
Serverless applications are much lighter than traditional server-oriented applications. They can scale up and down very fast and are metered on-demand through an event-driven model. This is why when a serverless application is idle, it does not cost anything to the user.
Serverless is a broad term to describe various cloud offerings that do not involve a server in the picture. When we go deeper into it, there are two significant categories of serverless applications—Backend-as-a-Service (BaaS) & Function-as-a-Service (Faas). Both of these are very different from each other.
BaaS refers to a setup in which backend systems are available for direct use in the form of an online service. The most common categories of such systems include authentication, databases, file storage, etc. Google’s Firebase and Amazon’s Amplify are good examples of the same.
FaaS refers to a setup in which users can package and deploy functions written in a programming language to a remote server that they can then invoke via APIs or events. These functions are identical to the native functions that you can write on your local computer, and they are invoked every time the FaaS API receives a request or an event.
Serverless Architecture, AKA FaaS, vs. PaaS
Now that you understand what serverless refers to, let’s take a moment to contrast it with the traditional server-oriented PaaS that has dominated the market until now.
To set some context, PaaS refers to Platform-as-a-Service, and it is used to run traditional server-oriented applications. Some famous examples of PaaS include Heroku and Google App Engine. PaaS and FaaS are often interchanged mistakenly because of how similar their designs are to one another. But, these two are entirely different architectures, and they are used in different scenarios.
PaaS allows you to run containerized applications on the cloud. This again means that you do not need to worry about provisioning and managing servers. But the deciding difference between FaaS and PaaS is that PaaS instances can not scale up and respond to varying requests as efficiently as FaaS instances. In fact, PaaS instances are not meant to do so; instead, they run 24x7 on a server and wait for incoming requests. On the other hand, FaaS instances are dormant until needed, and they can quickly scale up and down based on the traffic of the incoming request.
Some might argue that you can set up PaaS systems to auto-scale, emulating a FaaS set-up, but it is not practical to do so.
Serverless Architecture Examples
Having understood how serverless architecture works, let’s look at some of the examples of serverless architecture in action.
UI-Centric Applications
While you can use serverless architecture to build most types of applications, UI-focused applications are most popular and are relatively easy to implement with serverless too. Let’s take an example of a bookstore application. Traditionally, the application would consist of a book inventory database, a backend server to handle authentication, searching, purchase, etc., and a client user interface to allow users access to the store.
This is how a server-oriented design of the above application would look like:
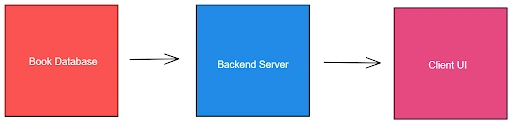
Using the serverless architecture, you can break down this application into the following modules:
- Books Database: To store the inventory
- Transactions Database: To store the record of purchases made
- Search Function: To search through the books database
- Purchase Function: To create a purchase transaction
- API Gateway: To navigate user requests to the right function
- Authentication Service: To authenticate users on the platform
- Client UI: To allow users to access the platform
This is how the new application design would look:
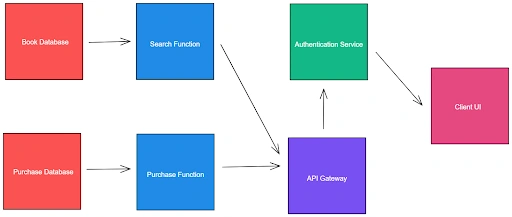
It is important to note that since the server is not in the equation anymore, the client has to be made more intelligent; i.e., the client will now contain the logic for keeping track of the user session, generating appropriate database requests, etc. Sensitive operations such as making a transaction will still be away from the client’s reach, but they will not be carried out on a persistent, traditional server. Independent FaaS instances would be invoked as and when necessary to handle such requests.
Backend Data Processing
Apart from building entire applications from scratch, many use the serverless architecture to build standalone backend data processing services. Many standard data processing operations can be built and scaled using the serverless architecture quite easily. Some common examples are:
Media Transformation
One of the most common backend operations is transforming media content. With a serverless function, you can set up pipelines that convert and provide your users with the proper media content format as and when needed. Netflix uses this technology to serve more than 70 billion hours of media content to its more than 60 million customers in more than 50 different formats.
You can also set up pipelines that convert and process media files as they are added to your storage bucket to ease the workload when a user accesses them. Common examples include generating thumbnails for videos or converting an MP4 video to M3U8 for easier streaming.
Real-Time Data Processing
Handling and processing raw data in real-time is another task that traditional servers are usually assigned. Serverless can turn out to be a good alternative in this scenario. You can structure your serverless function to process one record at a time and invoke it whenever you have some records to process.
In this way, you do not need to maintain a server session that will wait for data streams to provide it with data; instead, you can make the process asynchronous by letting the data stream trigger your function whenever it has a new record to be processed.
Custom Logic Workflows
Since FaaS functions are modular and independent of one another, you can create separate functions for various steps in your workflows and link them up together to create complex processes.
Most serverless providers like AWS and GCP provide seamless integration between their serverless products (Lambda & Functions) and other cloud products (databases, APIs, data streams, IoT, etc.), using which you can easily create a wide range of diverse workflows. You can even set these to trigger based on events instead of explicit invocations to make things even more seamless.
Advantages of Using Serverless
Serverless is undoubtedly among the hottest offerings in the market. Now that you know what it is and when to use it, it is time to look at some advantages of using serverless architecture over traditional structures.
Powerful Optimization
One of the most significant benefits of using the serverless architecture is the gain in performance and cost-optimization. From failsafe mechanisms to billing standards, you will definitely receive a boost in all of your metrics as soon as you switch to serverless.
Benefits of Event-based Operations
The serverless architecture runs on an event-based system contrary to the traditional stream-based systems. This means that each sub-part of your application is independent of one another, implying that failure or activity related to one event or sub-part of the system does not affect other sub-parts or events.
In an event-based system, modularising is easier. When your application receives a request or an event, it does not necessarily need to invoke each service; instead, the event can be directed to the suitable modules as necessary. This brings down execution time and running costs.
Increased Productivity
One of the most significant benefits of switching to a serverless architecture for your application is the productivity boost to your software team. Instead of worrying about managing and operating servers, the team can focus more on the product itself. Issues in network configuration/management or physical security of the server do not arise anymore since the FaaS provider handles them for you.
With serverless, your team can drop most of the DevOps that hinder the software development progress and focus on building a better product and writing high-quality code.
Better Observability
As mentioned earlier, the serverless architecture breaks an extensive application into smaller, easily manageable modules. Apart from the ease in management and fault handling, it also makes monitoring simpler. You can deploy custom, dedicated solutions to monitor each section of your app, and you can even prioritize between these sections while responding to issues.
Better observability also converts to better issue resolution. Instead of going through the complete application to fix any issue, you can identify and fix the segment that faults without affecting others. Similar to how modularity helps write reliable code, decomposition helps create reliable applications.
Reduced Costs
The next significant benefit offered by the serverless architecture is the reduction in various costs associated with developing an application. Let’s take a look at some of the significant costs that observe a good reduction when you switch from the traditional server-client architecture to a serverless one for your application.
Reduced Development Costs
Development takes up most of the cost and time of software teams. In most applications, there is a good portion that gets repeated all the time. Such parts include authentication, databases, file storage, etc. With the introduction of serverless Backend-as-a-Service, these portions can be easily commodified.
For instance, you can use commodified databases like Firebase’s Realtime Database or Cloud Firestore to set up a database for your application in minutes. These databases reduce a ton of set-up time you would otherwise have spent setting up your database server and instances. These are serverless, meaning you do not need to worry about or manage the physical device that your Firebase database is running on. You can simply focus on using it in your application in the most efficient way possible.
With the rise of serverless architecture, such services and offerings have become possible. Since their inception, the serverless BaaS products have made product development easier and more efficient.
Reduced Scaling Costs
Apart from reducing general application development costs, serverless technology has also lowered scaling costs. The whole premise of modularising your application and not worrying about a dedicated server paves the path for usage-based billing. This means that you only have to pay for the compute time and resources you use, and only when your app’s demands increase do your bills increase in proportion.
In other terms, this means that you do not pay the electricity and network costs of a dedicated server up 24x7 whether or not it receives user requests. In the serverless world, you pay per request and not by the hour. This pricing model is revolutionary for small load requirements as well as regular experimentation.
Additionally, the serverless billing model also works wonders for an application with irregular traffic. Say you rent a server with an up cap for 200 requests per hour. Now, if you have a usage schedule in which there are certain instances when you receive, say, 300 requests for a really short slice of time, say 30 seconds, you would either have to lose that traffic or choose a higher plan that can cover 300 requests per hour. If you decide to lose the traffic, you lose customers. If you choose the higher plan, you will be wasting money in the hours when you have less traffic. Autoscaling also would be ineffective since 30 seconds is not a timeframe wide enough to efficiently start and stop new server instances.
This is where the serverless model will shine. You can choose to pay for only the requests your application handles and not for the uptime or the requests cap. Your serverless app would automatically scale to accommodate the incoming traffic, however irregular it is. In the end, you will be billed according to the number of requests that you received.
Reduced Packaging & Deployment Woes and Time to Market
Apart from the traditional currencies, time is another precious resource. Not only does serverless reduce your monetary costs, but it also reduces your packaging and deployment issues. Since you do not need to worry about a server, deploying your code means just packaging it into a zip file and uploading it. There are no more start/stop commands, scripts, or decisions. The serverless provider handles all of this for you.
Some vendors go so far as to feature an IDE in their consoles themselves. This means that you do not need even a local setup on your machine for small or utility applications—you can use the in-browser IDE to write and deploy your application on the fly. This dramatically reduces the time to market for your app as well. If you face any issue in production, you can quickly bring up the in-browser IDE and make the changes. The updates roll out in minutes, and you can be back to normal before most of your users even know it.
Operational Support
Now that we know how serverless makes things easy regarding performance and cost, let’s look at the operations side of things. Handling and managing an application once it is coded is a huge responsibility in itself. The serverless architecture makes this part easy in many ways.
Faster Deployments, Greater Flexibility, Accelerated Innovation
As we discussed earlier already, serverless brings with itself the power to deploy faster. While it does reduce the cost and time associated with an application, another significant advantage that it offers is that you can innovate quickly and frequently.
With traditional architecture, experimenting with an application used to be a rather expensive choice. You had to write the new code and deploy it one by one on all your servers. The serverless architecture has simplified the coding part by allowing you to ship functions instead of applications. It has also sped up the deployment by making it seamless and super quick. Now when teams get new ideas to try out, they can hit the market much faster than they could do earlier with the server-oriented architecture.
More Focus on UX
Now that your software teams can focus on your application and not the infrastructure, you have much more time to dedicate to your application’s user experience. With the additional time, your teams can carry out user experience research; they can even use the serverless flexibility to roll out a large number of AB tests to check what fits well with your target users.
While this is not a cost-cutting technique, it does give you an edge over competitors who do not have the time and bandwidth to carry out such extensive UX research. A well-thought-out product is bound to go a long way in serving the customers’ needs and thus monopolizing the industry.
Great Support For Third-Party Vendors
With the modularised nature of serverless applications, third-party vendors play a prominent role in making your application’s development and deployment easier and faster. We already discussed commodified services such as authentication and databases earlier, which are offered by third-party vendors. But third-party support is not limited to just that. There are many more services that such vendors provide. Some examples include monitoring, payment handling, text translation, and more.
Potential Disadvantages of Using Serverless
While serverless seems to be the ultimate solution to all server woes, it is not the perfect replacement yet. Serverless brings with itself a long list of issues that make customers think before migrating their applications to this architecture. Let us take a look at some of them in this section.
Inefficiencies
Since we discussed the optimization advantages that serverless offered earlier, let us also take a look at the inefficiencies that it brings with itself. While not many, you cannot ignore these inefficiencies entirely. You have to consider them when deciding whether or not to rely on the serverless architecture for your application.
Long-Running Application Costs
Serverless applications are great for short jobs. You can easily have a new application instance start every time you receive a user request. But if your application’s workload is long-running, serverless might not be the best option for you. The serverless billing model considers your application's total effective running time to determine your monthly costs.
If you run long-running tasks, the costs of your serverless instance would drastically rise. It is better to switch to the traditional dedicated server model for long-running jobs.
Cold Starts
A cold start occurs when a serverless function is invoked, and internal resources need to initiate. Cold starts take longer than usual since they initialize all the necessary internal services and other resources. If your serverless application receives requests after long intervals, it might have to start cold multiple times, which will increase the execution time.
However, this is avoidable. You can send requests periodically to your serverless app to keep it in an active state. This will ensure that your app does not start cold often and that your users get the best experience possible.
Vendor Concerns
Next up in the list of cons is vendor issues. Since cloud vendors offer serverless as one of their services, it is prone to have problems specific to them. Here are some of the major concerns that users generally have with their serverless vendors.
Third-Party Dependencies
The serverless architecture requires you to rely on your cloud provider. This means that the underlying technology can change at any time without notice. While it is harmless in most cases, it can sometimes affect your application and cause unnecessary downtime.
Also, if you use a third-party serverless commodified service in your application, you need to be aware of the updates rolled out in the service. Like your usual code dependencies, you need to check your serverless dependencies as well, which can be a tedious task.
Vendor Lock-in
Vendor lock-in refers to the situation in which you are tied to a particular vendor because the services you used with them are not available in the same way from other competitor vendors. This means that if you were ever to change your vendor in the future, you would have to update your operational tools such as deployment, monitoring, etc. You might even be forced to update your code or change your design/architecture to accommodate the new vendor.
Even if you can make the changes in one of these aspects, there is a high chance that it would be difficult to migrate other aspects of your application to the new vendor. This means that moving your application from one vendor to another is not possible without investing time and resources into adapting your application on a much lower level appropriately.
A solution to this is to use a multi-cloud approach. In a multi-cloud approach, the application is designed and built in a platform-agnostic way. This includes considering the possibility of changing your cloud vendor early in the design and making room for the change wherever possible. While this is costlier than usual, this does make sure that you face minimum friction when moving from one cloud vendor to another.
Multi-Tenancy Issues
Multitenancy refers to a situation where multiple instances of applications for various customers run on the same machine and possibly on the same host environment. This is how cloud vendors achieve the economy of scale benefits that we have talked about so far. While the vendors try to make the customers feel that they are using only one system each, they often run into security, performance, or robustness issues.
There have been cases when one customer has been able to see or access another customer’s data, an error in one customer’s application has caused a failure in another customer’s architecture, or a high-load application of one customer has caused another customer’s application to slow down. While these are rare and can happen with other architectures that rely on multitenancy, you can not entirely ignore these.
The best way to avoid running into a multi-tenancy issue is to stick to the premier, seasoned cloud vendors. AWS Lambda is one good alternative that has been around for quite some time. However, if you have to use some other cloud vendor, please ensure that you are ready to handle such issues.
Security Concerns
The serverless architecture opens your application up to a whole new set of security problems. Here are a couple of those:
- Each serverless vendor that you use in your application ecosystem has its own set of security implementations. The addition of more and more such security implementations increases the chance for attackers to find a loophole in your app’s security.
- If you use a commodified service directly in your application, you lose the security advantage that an in-house server-based service would have offered. It is essential to weigh the ease of use against the loss in security before selecting a commodified service.
Lack of Dedicated Server
Since serverless technology is all about getting rid of servers, you might miss out on some of the best offerings by a server-oriented architecture. Here are some of the main discomforts you might face due to the lack of an actual server.
Loss of Server Optimizations
With an utterly serverless setup, there is no room to implement optimizations in your server design. For instance, a ‘Backend for Frontend’ pattern exists to abstract certain underlying aspects of your entire system within your server. It helps the client to perform operations more quickly and use less battery power in the case of mobile applications. But such optimization is not available in a BaaS environment since you are no longer in charge of designing your server.
A FaaS environment is still better since you have some control over the server-side code of your application. However, you will still miss out on fine control over your backend code in the case of serverless architecture.
No State Persistence for FaaS
One of the biggest issues with FaaS architecture is no local state persistence. You can not assume that the state from the previous execution will be available in the following invocation of the same function. While this conforms to the definition of a function, it does not make much sense in the context of the backend.
One way to solve this issue is to make your functions entirely stateless and depend on an external data source for all the data or state you need in an invocation. But this can get a lot slower than in-memory or on-machine alternatives. Therefore you need to ascertain if this solution will be viable in your case or not.
In the case of FaaS, some providers allow the use of local cache to retain states for some time. However, these are at most for a few hours and can not be wholly relied on. You can consider bringing in low-latency external caches like Redis or Memcached to extend this functionality. But just like any other external dependency, this will require extra efforts and can be a bottleneck in terms of speed or performance.
What’s Next for Serverless?
Serverless is a style of application architecture that does not rely on managing traditional servers; instead, it narrows the developer’s responsibility down to managing their code only. Serverless systems are modular and independent, and they can be invoked and shut down very fast seamlessly and can be triggered via system events too.
While serverless seems like a significant optimization on the traditional server-oriented cloud architecture, it does not fit well in all scenarios. The current shortcomings of the technology limit us from using serverless as the mainstream cloud architecture. Nevertheless, the optimization that it brings in its use-cases is unmatched. The technology is set to develop and grow in leaps and bounds in the coming future.
For more in-depth content around web development and a reliable tool for optimizing your application’s performance, navigate our blog and feel free to explore ScoutAPM with a free 14-day trial!




