Distributed Monoliths vs. Microservices: Which Are You Building?
 Ganesh Mani
on
February 08, 2022
Ganesh Mani
on
February 08, 2022

The concept of microservices has been popular for several years. As a result, many developers, companies have started building their applications using a microservices architecture. There are several reasons why a company or developer would want to move to microservices, including building a scalable application, maintaining the developer’s productivity without relying on each other, etc.
Your teams start to build microservices by containerizing applications etc. But, once the application begins to grow, you start noticing problems such as changes in one service affecting another service, developers hesitating to change functionality in a service, services taking a long time to start, and more.
But we wanted to solve those problems with microservices, right? How did they happen in the microservices architecture? Well, if this sounds familiar, your application is moving towards the microservices antipattern: distributed monolith. In this guide, we will break down both of these architectures to understand and make a conscious decision based on your requirements.
Feel free to navigate the guide using these links:
- What is a Distributed Monolith?
- What’s Wrong With Distributed Monoliths?
- Distributed Monoliths vs. Microservices: How To Tell The Difference
- How To Build Microservices and Steer Clear of Distributed Monoliths
- Closing Thoughts
What is a Distributed Monolith?
Distributed Monolith is a system that resembles the microservices architecture but is tightly coupled within itself like a monolithic application. Most people misunderstand the concept of microservices. It is not just about splitting the application entities into several services and implementing CRUD operation using REST API on top of them. Besides that, communication between those services should happen only in a synchronous way.
Building a microservices-based app comes with a lot of advantages. But while making one, there are good chances that you might end up with a distributed monolith.
Your microservice is just a distributed monolith if any of these apply to it:
- A change in one service causes the re-deployment of other services.
- Your microservices rely on low latency communications.
- Many services in your application share a resource (such as a database) which makes them tightly coupled.
- There is a shared codebase or test environment between microservices.
What’s Wrong with Distributed Monoliths?
One of the primary reasons to build an application using microservice architecture is to have scalability. Therefore, microservices should have loosely coupled services which enable every service to be independent. The distributed monolith architecture takes this away and causes most components to depend on one another, increasing design complexity.
Once an application is decoupled into different services, it is easy to change its tech stack, scale it up or down based on requirements, and more. It also means that a service can be independent without worrying about other services. But in the case of a distributed monolith, changes in design, implementation, or behavior of one service can cause changes in other services. As a result, It can badly affect performance and productivity. Here are some other top disadvantages of using a distributed monolith architecture over a microservice-based one.
Requires Low Latency Communication
A significant problem with a distributed monolith is latency. If your services are tightly coupled and depend on synchronous communication between several services, it will badly affect the application’s throughput.
Synchronous communication induces high latency. Let’s say that Service A sends a request to Service B, and it takes a while to respond. It can be a crash or slow server etc. Due to that, Service B increases the overall latency of the communication and affects application throughput. It completely defeats the purpose of implementing the microservice architecture.
Services Don’t Scale Easily.
Scalability is one of the benefits of using microservice architecture. When services are loosely coupled, it is easy to scale a particular service without affecting other services.
When it comes to the distributed monolith, scaling one particular service involves deploying new instances of the dependent services and all their dependencies. It is a time-consuming and resource inefficient process that you can avoid by adequately implementing the distributed systems.
Dependency Between Services
Distributed monolith has dependency between services, i.e., it is tightly coupled. Because of that, it is difficult to change the business logic in one service. On changing that, it requires the other dependent services to re-deploy. Thus, it affects both customer experience and developer’s experience. Once the application starts to grow, changing a simple functionality in one service can take days to make it live for the users.
Impact on Productivity
Distributed monolith can badly affect the team’s productivity. Implementing a new feature on top of existing services can become cumbersome. For example, let’s say in a distributed monolith, two services share the same database, and you want to introduce a new service that changes the existing structure in the database. The team has to work on the existing services to make them work and implement new services to implement new features.
Every time there’s a change, developers need to rework existing ones. It completely negates the purpose of microservices architecture. On top of slow deployment and performance issues, we’re adding operational complexity now without even having the benefits of microservices.
Distributed Monoliths vs. Microservices: How To Tell the Difference
We all want to start with the goal of building microservices. But, sometimes, the implementation can turn the application into a distributed monolith. It may be because of some bad decisions or application requirements, etc. To identify whether a system is of microservice architecture or just a distributed monolith, there are some factors and behavior of the system that you can look out for.
Shared Database
If your distributed services share the same database, it’s not a distributed system. It’s a distributed monolith. For instance:
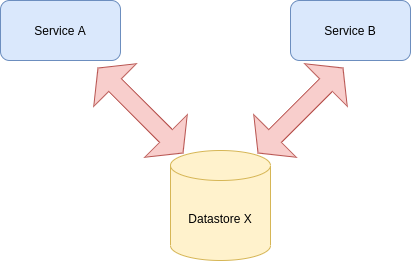
Two services share the same datastore.
Service A and Service B share the same datastore here. So, if your Service B requires a change in the data structure in Datastore X, it will also affect Service A. Thus, it creates a dependency and makes the system tightly coupled.
Small changes in the data can affect the other services here. In a microservice architecture, it should ideally be loosely coupled. To give a real use-case, If there’s a change in the data structure of the user table in an e-commerce application. It should not affect other microservices such as products, payments, catalogs, etc. If that change makes your application redeploy all other services, it can badly affect the developer productivity and customer experience.
Shared Codebase/Library
Despite having independent codebases, microservices can fall into the trap of shared codebases or libraries. The problem with shared libraries is that frequent library updates can affect the dependent services and re-deploy the services. Thus, it makes the microservices inefficient and prone to changes.
For example, let’s say you use a private auth library across different services. When a service needs a change in the auth library and updates it, it will force all other services to redeploy to receive the changes. This will push your app’s design towards that of a distributed monolith. A standard solution here is abstracting the library and using a custom interface to interact with it. While it might seem redundant, it is better to have redundant code than tightly coupled services in the microservices world.
Synchronous Communication
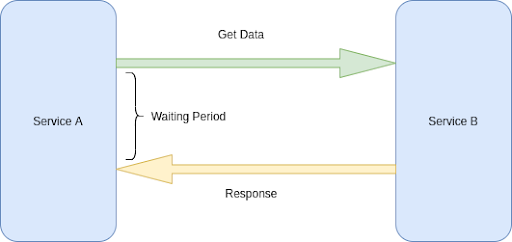
Synchronous communication between two services increases coupling.
You can say service A depends on service B if it either needs data or any data validation from B. It is because both services are in synchronous communication. So if service B goes down or delays the response, it can affect the throughput of service A. if your application has too much synchronous communication between services, it can be a distributed monolith, even if it implements the microservice architecture.
Shared Deployment/Test Environments
Another critical aspect of implementing microservices architecture is continuous integration and continuous deployments. If your services use a shared deployment or common CI/CD pipelines, then every time you deploy one service, it will re-deploy all other application services even though you didn’t change anything in those services. It affects the customer experience and adds unnecessary load to the infrastructure. Microservices need to have independent deployments to make the services loosely coupled.
Another criteria to identify the difference is via shared test environments. Just like deployments, a shared test environment brings in some coupling between services. Imagine a service that has to pass a brief performance test before its final deployment to production. The main reason why this step exists is to test the performance of the specific service. However, suppose this service shares the test environment with another service that runs the performance test simultaneously. In that case, it can affect both services and make it hard for the system to detect any anomalies.
Tightly/Loosely Coupled System
Since we already discussed what a tightly or loosely coupled system means in microservices, let’s discuss the difference between the two and why microservices need to be a loosely coupled system in this section. To understand whether your system is just a distributed monolith or not, let’s take an e-commerce application as an example here,
When a customer views a product, it queries the product details from the server and renders it on a page. Using traditional monolith, we can create a simple MVC-based application that connects the frontend and backend.

We all know the problem with traditional monolithic applications. When the backend crashes, the whole application goes down because the application is tightly coupled. To migrate the same application to microservices, we split the functionality into separate services keeping the same database for all the services.
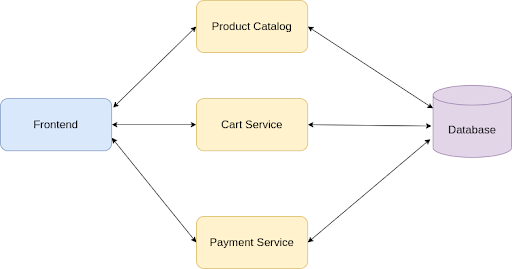
Splitting a simple backend+frontend app into its constituent services.
It still makes the application crash if any one of the services goes down. Also, if a product catalog service needs data about users, it needs to make an API call to the user service and complete the request. Thus, it increases the latency of the application and affects the application throughput. And, it still makes the system tightly coupled and doesn’t follow microservices best practices.
To make it efficient and robust, we can split the services that are independent of each other.
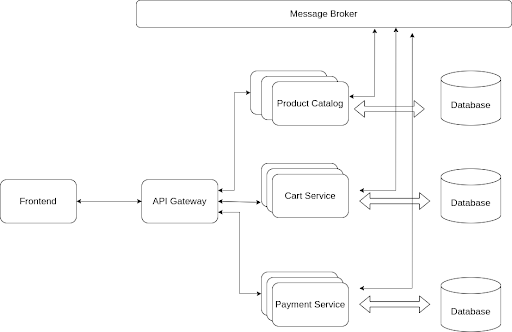
Defining microservices for each entity in the ecommerce app.
Here, we break down the application into services, and each service has its database. The client can access the application using an API gateway that aggregates different APIs from different services. In addition, services can communicate asynchronously, which makes the whole architecture loosely coupled. In microservices, asynchronous communication helps to achieve scalability by avoiding low latency communication.
How to Build Microservices and Steer Clear of Distributed Monoliths
So far, we have seen distributed monoliths and their differences with microservices. So, let’s discuss the best practices to build a microservice and avoid turning it into a distributed monolith. But, before getting into the how part, let’s start with monoliths.
Don’t get me wrong; Microservices have a lot of advantages over traditional monoliths. But, a monolith is the best option when you’re starting to build an application. Because one of the significant constraints while building microservices is not creating the service itself, it’s setting the boundaries between services.
Once you understand the boundaries to define for your application, building services will become a more straightforward process. First, however, you need to keep some best practices in mind to avoid building a distributed monolith in that process.
One of the most essential best practices to follow while building a microservice is to have a loosely coupled system. We have already discussed in length how a loosely coupled system goes into making a robust and scalable microservices architecture. This section will throw some light on how you can design loosely coupled systems that can further evolve into reliable, scalable microservices.
Database Per Service
We can make a system loosely coupled by splitting the database and its entities per service. To give an example, let’s say that services A and B share the same database.
Two services share the same datastore.
We can split the entities into two different databases, and each service can use only the specific database. In that way, any changes in the data made due to one service will not affect the other service.
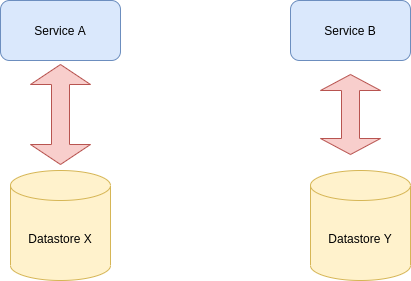
Two services use their own copies of datastores.
Here, service A will only use Database X, and service B only uses Database Y. Data can be redundant, but that’s the tradeoff to keep the system loosely coupled. So now, even if we change anything in service A will not affect service B.
Independent Codebase/Libraries
Like distributed databases, the system should have separate private libraries for each service. A private library should belong to a particular service. As discussed before, it helps to avoid dependency between services and build a robust and efficient microservice architecture.
If there’s a change in a private library that belongs to a specific service, it won’t affect other services.
Decoupled Infrastructure and Deployment
Most of the work while building microservices is architecting and deploying the distributed system. In that way, having an independent and well-architected infrastructure with well-defined continuous integration and deployment processes helps build microservices efficiently.
Asynchronous Communication
Synchronous communication in a distributed system can badly affect the performance and app throughput over time. However, it does not mean we should avoid synchronous communication altogether. On the contrary, in a distributed system, we can achieve the same using asynchronous communication.
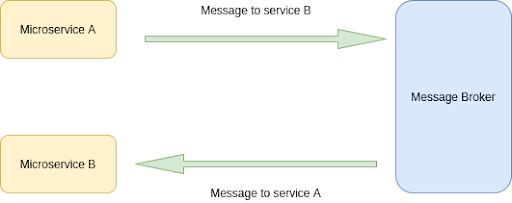
Asynchronous communication is the type of communication in which a request is made to a service, and the subsequent response occurs independently from each other. It makes the system loosely coupled and avoids dependencies between the services.
Event Sourcing
In a distributed monolith, it is difficult to capture events across the system. Because, In a monolith, we only store the current state of data in the data store. But event sourcing captures every action. Here, an event is a fact representing some action that happened in the system.
You might wonder how event sourcing solves the problem of the distributed monolith. Here’s how it does:
- The event store has event logs that are not coupled with any service datastore. Instead, it’s a central part of the system that can log all the events happening across the system.
- Event sourcing and events are immutable that means once it happens, we can’t update. We can only add new events to the system. So, it’s hard to change the action history and easy to track
- Event sourcing is reproducible. We can reproduce by replaying the log of events. So that, even if the system fails in the middle of a transaction. We can resume from that point.
Event sourcing provides a lot of advantages to a distributed system. Here are some of them
One Source of Truth
Instead of relying on multiple datastores, the event store acts as a single source of truth to analyze the application state. For example, let’s take an ecommerce application, where a user searches for a product, selects and adds it to the cart, and tries for a payment. Let’s assume that the payment service was down and failed. When the payment service recovers and comes back online, our event store helps start from that point instead of starting from zero.
Common Data Format
The data format of event logs and stores for the microservices is shared across all the services. It will be plain text that represents the state of action and data changes. For example, a user adds an item to a cart as an action, and the event describes it as an “item added to cart.”
Closing Thoughts
Building a microservice is not just about splitting and repackaging a monolithic application into several services. It requires changing the fundamental application architecture such as communication, data transfer between services, and more. Regardless of whether you are building a microservice-based app from scratch or restructuring a monolith app, it is crucial to follow the best practices, strategies and monitor metrics using performance monitoring tools. That way, you can maintain the application’s sanity and its architectural foundation.
There are good chances that a microservice might end up as a distributed monolith if it’s not following the best practices. But, at the same time, when your microservices application continues to grow, monitoring your application is essential. Make sure to check out Scout’s performance monitoring and error tracking services for your next microservices project!




