Ractor: Ruby’s Version of the Actor Model
 Kumar Harsh
on
January 26, 2021
Kumar Harsh
on
January 26, 2021

Concurrency has always been an important factor in determining the feasibility of a programming environment. If your programming language can run multiple threads or workers, it can manage to do much more work in parallel, thereby providing better use of resources. Ruby 3 introduces an experimental feature called Ractors (previously known as Guilds) which is set to fix all your concurrency woes! Ractors are proposed to be fast, efficient, and thread-safe workers which will manage the execution of Ruby code seamlessly. In this article, we take a look at what Ractors are, their origin, the advantages of using them, and a well-defined tutorial covering the basics of setting up ractors in your project.
Use these links to navigate the guide:
- Ruby “Guild” is Now “Ractor”
- What were Guilds?
- How were Guilds meant to be used?
- Why the Name Change?
- Ractors vs Guilds
- What are the Benefits of Using Ractors?
- Parallel Execution
- Mitigating Thread Safety Issues
- How to Create and Use Ractors in Ruby
- Push Type Messaging
- Pull Type Messaging
- Copying vs Moving
- Building a Web Server using Ractors
- Recap
Ruby “Guild” is Now “Ractor”
The origin of Ractor dates back to 2016 when Koichi Sasada (designer of the Ruby Virtual Machine and garbage collection) presented his proposal on a new concurrency model for Ruby. Before this, Ruby did have a concurrency model, but it came with a Global Interpreter Lock (GIL), disallowing developers to run threads in parallel with each other. Background calculations and foreground UI changes could still run together, but the code was not allowed to be split into multiple threads. This was put in place to curb the possibility of thread deadlocks and race conditions, but sooner than later, the creators of the language realized that they need to provide Ruby developers with a better model of concurrency. This new model was aimed at freeing the language from the GIL, as well as ensuring that no thread-safety issues arose because of it.
Back in 2016, Koichi talked about the issues of multi-threaded programming in his presentation at Ruby Kaigi as well as some common ways of solving them. Along with that, he also presented his concept of Guilds for the first time. Before we move on to Ractors, let’s take a moment to understand the bare-bones of Ractors - Guilds.
What Were Guilds?
Guilds were meant to be a new concurrency abstraction for Ruby. A guild would host one or more threads, and each thread, in turn, would host one or more “fibers”. Threads in two different guilds could run in parallel, but threads in the same guilds couldn’t. This would be ensured via a new lock called GGL, the Giant Guild Lock. Every guild was to have its GGL, which it could provide to only one thread at a time. Also, all guilds would have their own set of mutable objects, and one guild would not be able to modify another guild’s objects. This was proposed to prevent data inconsistency issues due to concurrent access.
Guild::Channel interface to facilitate copying or moving of objects between themselves. transfer(object) was proposed to allow sending a deep copy of the object to the target Guild, and transfer_membership(object) was proposed to allow moving an object from one Guild to another completely. But all this was for mutable objects only, as immutable objects do not pose a risk of data inconsistency. This is so because once immutable objects are assigned a value, it does not change throughout the execution of the program, so any Guild trying to access an immutable object’s data will always be returned the same, consistent value. Immutable objects would be shareable across Guilds for read operations, as long as they were deeply frozen, meaning that every object that they referenced or contained was also immutable.
How Were Guilds Meant To Be Used?
In his proposal, Koichi talked about several ways in which guilds could be used. Some of them are:
Master-Worker Type
This architecture suggests running one guild as the parent, and one or more other guilds as its children in parallel with each other. This model relies on delegating repetitive operations to worker guilds, to keep the main guild unoccupied. Koichi explained this architecture further by citing a Fibonacci example, in which he showed how fib(n) could be calculated using a worker guild. Here’s the code from his proposal:
# Assuming fib to be the method used to calculate the nth term of the Fibonacci sequence
def fib(n) ... end
# g_fib is the worker guild here, which calls the fib(n) method on a different thread than the calling environment
g_fib = Guild.new(script: %q{
ch = Guild.default_channel
while n, return_ch = ch.receive
return_ch.transfer fib(n)
end
})
# Guild::Channel interface is used to pass messages between guilds
ch = Guild::Channel.new
# Send the argument for fib(n) as well as the communication channel to g_fib
g_fib.transfer([3, ch])
# Print the result from g_fib
p ch.receiveg_fib, multiple guilds can be created and run in parallel to process a greater number of operations concurrently.Pipeline Type
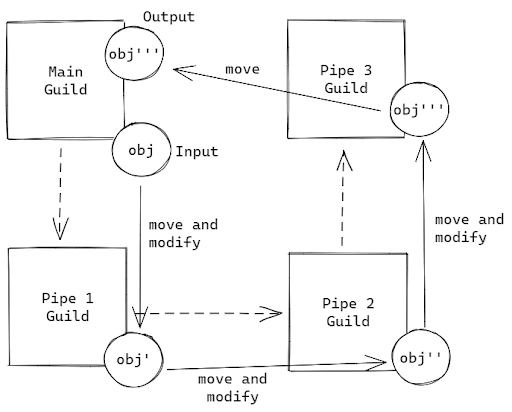
This architecture suggests running multiple guilds in sequence, passing the result of one guild to another in the list, and so on. This would imitate a pipeline, and help in accommodating solutions for problems, which require a builder pattern i.e filters or inputs have to be applied step-wise to achieve the desired result. Each step would comprise of a guild, meaning that sub-tasks could be easily broken down internally and run in parallel for faster computation. Here’s an example implementation from Koichi’s presentation for the same:
# Create a channel for receiving the final result
result_ch = Guild::Channel.new
# The third & final step of the main task
g_pipe3 = Guild.new(script: %q{
while obj = Guild.default_channel.receive
obj = modify_obj3(obj)
Guild.argv[0].transfer_membership(obj)
end
}, argv: [result_ch])
# The second step of the main task
g_pipe2 = Guild.new(script: %q{
while obj = Guild.default_channel.receive
obj = modify_obj2(obj)
Guild.argv[0].transfer_membership(obj)
end
}, argv: [g_pipe3])
# The first step of the main task
g_pipe1 = Guild.new(script: %q{
while obj = Guild.default_channel.receive
obj = modify_obj1(obj)
Guild.argv[0].transfer_membership(obj)
end
}, argv: [g_pipe2])
# Create the input object, to be passed into the first step
obj = SomeClass.new
# Pass the input object to the first step
g_pipe1.transfer_membership(obj)
# Wait for the result from the channel, which will receive the result from the final step
obj = result_ch.receiveHere’s how the architecture would look conceptually:
Special Parent Type
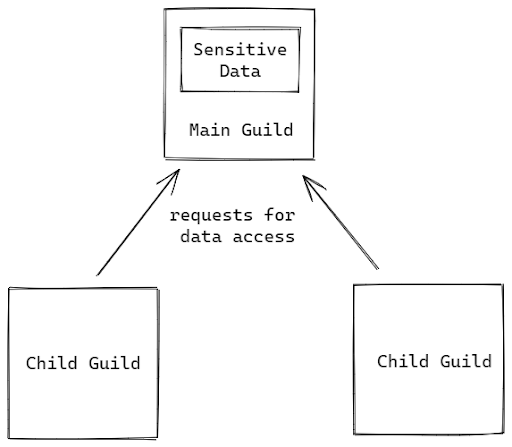
This architecture builds upon the master-worker one but adds another level of isolation by confining the moving parts of the system to only the parent Guild i.e. the data, mutable objects, etc will be stored in the parent Guild only, and the children Guilds can access it when needed. This ensures that one single source of truth exists at the parent level in the system and that every child has an equal chance and way of accessing and operating using it. This also enhances security, as every change can be logged as a transaction by the parent at one place, and illegal operations can be blocked right away. Koichi presented a banking example, in which he demonstrated one parent bank Guild to hold all the bank data, and other children Guilds to access it when needed. Here’s the example from his presentation:
# The parent guild, which houses access to sensitive data, such as the Bank object
g_bank = Guild.new(script: %q{
# Wait for incoming requests from other guilds in form of messages
while account_from, account_to, amount,
ch = Guild.default_channel.receive
# Parse and operate on the incoming data
if (Bank[account_from].balance < amount)
ch.transfer :NOPE
else
Bank[account_to].balance += amount
Bank[account_from].balance -= amount
ch.transfer :YEP
end
end
})
...If you look at a conceptual diagram for this architecture, you’ll realize that this is the same as the master-worker concept, but the only key change is that the data, resources, etc lie with the master Guild only.
Why the Name Change?
Several, mixed reasons have been doing the rounds on the internet trying to form a theory explaining the name change. While some people believe that this was done to make sure that non-English speakers did not have an issue with pronunciation, some others believe that “Ruby” and “Guild” are already filled with a lot of trade unions, gaming, etc references which is why a dedicated, unique name would make things simpler for developers.
On the contrary, the team states that the new concurrency model is very similar to the Actor model in languages like Erlang, Elixir, etc. Therefore they have joined Ruby and Actor to form the new name - Ractor. While a lot of people still confuse it with Reactors, the name is certainly unique to Ruby. It's just a matter of time until it picks up the pace and becomes a common term among developers who advocate multi-threaded programming.
Ractors vs Guilds
While Guild was a concept proposed by the creators, Ractor is an actual, concrete implementation of it. This is why a few differences are bound to exist. Talking about the fundamentals, a Ractor still composes itself with threads, and two threads in the same Ractor can not run simultaneously. However, two threads in two different Ractors may run simultaneously if needed.
Ractors communicate similarly to Guilds: you can share immutable objects directly, and mutable objects via message passing in which an object can be either copied and sent over or moved entirely, thereby freeing the sender Ractor of the rights over the object. So as you can see, there is absolutely no difference between Guilds and Ractors other than the fact that “Guild” was a conceptual proposal, which has been implemented concretely in the latest version of Ruby by the name “Ractor''. While some may claim that this has been done to make the module look similar to the Actor model, but as guilds were similar to the Actor model as well, it does not make any significant difference.
What are the Benefits of Using Ractors?
While you might feel hesitant in rewriting your legacy apps in a multi-threaded fashion just because Ruby’s trying out threads for the first time, it is important to understand the vast sea of possibilities this opens up for process management. Two key points that the new feature builds upon is improved performance and reinforced safety.
Parallel Execution
tak function by first executing it 4 times sequentially and then 4 times in parallel with ractors. This has been taken from the official release notes of Ruby 3.Here’s the sample code:
def tarai(x, y, z) =
x <= y ? y : tarai(tarai(x-1, y, z),
tarai(y-1, z, x),
tarai(z-1, x, y))
require 'benchmark'
Benchmark.bm do |x|
# sequential version
x.report('seq'){ 4.times{ tarai(14, 7, 0) } }
# parallel version
x.report('par'){
4.times.map do
Ractor.new { tarai(14, 7, 0) }
end.each(&:take)
}
endHere are the results of the two runs:
Benchmark result:
user system total real
seq 98.063000 0.016000 98.079000 ( 98.448813)
par 149.000000 0.094000 149.094000 ( 37.665263)As you can see, the time taken to complete the jobs sequentially is nearly 3 times more than that needed to complete the jobs running in parallel with each other. This is how parallel processing saves on execution time. It is important to note that this may not be so beneficial in every case, as sometimes rewriting some programs using multithreading can make them unnecessarily complex (refer to the dining philosopher’s problem), and sometimes multithreading does not make any difference in the execution efficiency of the program (usually in single-core-processor based machines).
Mitigating Thread Safety Issues
Ractors make your program thread-safe. While not entirely (which we’ll talk about more later), Ractors do provide the primitive thread concept another layer of thread-safety with the help of their resource sharing rules. Before we dive into the ‘how’, let's take a look at where the thread safety issue comes from.
The Problem
When dealing with threads, a term that you’ll often come across is race condition. Race condition is a situation in which a system (via multiple threads/processes) attempts to carry out two or more operations on a common memory reference at the same time. If not handled properly, the outcome of this situation is that the net result of the two operations becomes dependent upon the order in which they were carried out on the processor’s level. Ideally, the outcome should be independent of the sequence of execution, and should always be the same.
Here’s a good example to understand the term better - imagine you had the following loop:
$x = 0
for i in 0..100000
# increment x by 1
$x = $x + 1;
endIf you run this on 5 different threads, you’d naturally expect the final value of x to be 5 times 100000. But in thread-unsafe environments, it will rarely be so. The reason is that even though the code inside the loop looks to be a one-liner, it is not executed at once by the runtime. Here’s how a conceptual breakdown of the increment x line looks:
1. copy current value of x into a temporary variable/register
2. increase the value by 1
3. store the new value back into xWhile this may seem linear, it creates chaos when run in a multi-threaded environment without any safety provisions. The catch that comes in here is that while a thread (say thread 1) is on step 1, i.e. it has copied the value of x, another thread (say thread 2) might be finishing its cycle, i.e. it might update x to a different value. This way, once thread 1 comes back to update the value of x after incrementing it, the current value of x might already be equal or greater than thread 1’s new value for x. Let's say x is 5 when a thread begins its cycle. If another thread increments the value of x to 6 while the first thread is in its substep 2, it will still come back and try to update x with the incremented value of its temporary variable, which will still be 6. This will result in the final value of x being 6, while ideally, it should have been 7 after increments by two threads. This clearly makes the result inconsistent.
The Solution
One popular solution to the race condition is to introduce locks. The MRI (Matz’s Ruby Interpreter) houses a GIL (Global Interpreter Lock) which does not allow threads to run in parallel with each other at all. You can still make threads, and split tasks onto multiple cores of your processor, but the GIL ensures that only one core is running any task at a time. This makes processing sequential, defying the meaning of threading, but solves our problem. The system is still concurrent, as multiple threads can still be created, and each of them will complete their tasks independent of one another.
With the introduction of Ractors, the creators have attempted to lift the global lock for the first time. Ractors facilitate parallelism, i.e. if you have a processor with multiple cores, Ractors can utilize them to run code on multiple cores at once, implementing true parallel execution. To curb race conditions, some limitations on sharing have been imposed. Most objects are unshareable, while those which can be shared are protected by an interpreter or lock mechanism.
The Trouble
While Ractors are said to be thread-safe on their own, they’re not fully thread-safe when combined with the existing APIs in Ruby yet. If you are not careful while using modules or classes with Ractors, you might accidentally introduce race conditions. While not much is available on this as of now, we will have more anecdotes of Ractors going berserk when combined with modules/classes as the community explores the new feature further.
Another important point to note is that the message-passing APIs provided with Ractors right now are blocking in nature (send, yield, take, etc) and if these are not structured carefully in a program, it might result in a dead-lock or a live-lock.
These gray areas in thread-safety in Ractors are a sensitive topic for the creators at the moment. A lot of work is currently being done to ensure that these issues are resolved, which is the main reason why Ractors are being called experimental, and there is a warning being issued with the output when you use the module in your code, stating that the behavior of the module may change in the future, and also that there are a lot of implementation issues right now. However, the use of ractors certainly simplifies debugging - if you do not use ractors, you may need to trace a large chunk of your code to identify the cause of those issues, while with ractors, you can confine your search to the code that has been shared with Ractors.
How to Create and Use Ractors in Ruby
Now that we have taken a deep look at the origin and purpose of Ractors, it is time to get our hands dirty with code!
Here’s how you can create a Ractor:
ract = Ractor.new do
# Code to be run in parallel with the main Ractor goes here
endname is such an identifier that you can pass to a Ractor when creating it so that if you ever decide to change reference variables, the ractor is still able to distinguish itself from others. Here’s how you can do that:ract = Ractor.new name: 'my-ractor' do
# Code goes here
end
# Ractor#name returns the name that you passed earlier
ract.name
# => 'my-ractor'As you can see, each Ractor takes in a block that contains the code that is expected to run in parallel. The presence of a block opens up the possibility of passing in arguments. But it does not happen the traditional way here. Instead of treating the block arguments as arguments, Ractors treat them as messages. All communication in and out of Ractors happens through messages. Here’s how you can pass an argument to a Ractor’s block:
ract = Ractor.new 42 do |arg|
arg # returning arg
end
# Expecting a result from ract
ract.take
# => 42Ractor.new call becomes an argument for the trailing block. But as mentioned previously, it does not happen instantaneously like it would with a generic block. Rather it waits for the Ractor to ask for a message and then provides it with the argument’s value. In effect, the parent ractor pushes a message to the child ractor’s message queue, and then the child ractor acts on it. This introduces the push type messaging paradigm with Ractors. Before we go into that, let’s take a glance at how message passing works in Ractors.Each ractor has an incoming message queue of unending size linked with it. Ractors communicate by sending objects to each others’ message queues.
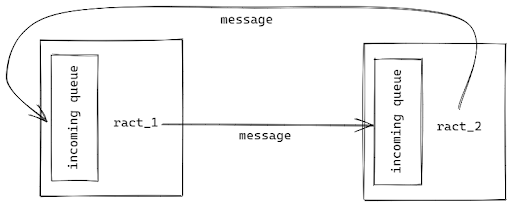
But the process of sending is controlled to facilitate two ways of communication, namely push-type messaging and pull-type messaging.
Push Type Messaging
Ractor#send call. The child ractor can then choose to retrieve it using a Ractor#receive call. If the child tries to retrieve a message in an empty queue, it gets blocked and then has to wait for a message to be passed to it. Any number of messages can be queued up using this approach, and the child will be able to access them sequentially, or by using a filter condition.Here’s how you can push messages to a child ractor:
ract = Ractor.new do
msg = Ractor.receive
msg
end
ract.send 42
ract.take #=> 42receive_if method can be used to filter through multiple messages that have been passed in. Here’s an example:ract = Ractor.new do
msg = Ractor.receive_if{|msg| msg < 50 } # => 42
msg
end
ract.send 59
ract.send 55
ract.send 42
ract.send 51
# The result will be based on the message that got through
ract.take #=> 42Pull Type Messaging
Ractor.yield(obj). It is a blocking call, i.e. if there is no Ractor.take call complementing a Ractor.yield call, the yield call will block the control. And if there’s no Ractor.yield call for a Ractor.take call, the take call will block the control. Here’s how you can use this type of messaging:ract = Ractor.new do
Ractor.yield 42
Ractor.yield 84
end
ract.take # => 42
ract.take # => 84Ractor.take. This validates the fact that ractors return their result in the form of outgoing messages, similar to how they take arguments in form of incoming messages.Copying vs Moving
We’ve talked a little about object-sharing in the thread-safety section. Building on that, let’s now understand the two types of object sharing that are allowed in Ractors.
obj is passed into the Ractor.yield(obj) or Ractor.send(obj) call. In effect, a copy of obj is created and sent to the recipient ractor. On the other hand, you can move obj to another ractor using a Ractor.yield(obj, move:true) or Ractor.send(obj, move: true) call. The key difference between the two is that if the sender ractor tries to access obj after it has been moved, Ruby will raise an exception, while there would be no such exception on accessing obj if it were sent by copying. Building a web server using Ractors
Now that we’ve brushed up on our basics, let’s take a shot at building a realistic, concurrent web server using Ruby Ractors!
Let’s begin by scaffolding a generic, non-Ractor based web server in Ruby:
require 'socket'
server = TCPServer.new(8000)
while session = server.accept
request = session.gets
session.print "Hello world!"
session.close
endwhile loop that accepts incoming connection is sequential, and if a new request comes while the server is busy handling one, it will have to wait until the server completes the previous request and becomes idle. In practical scenarios, this is not desired. There are solutions like Sidekiq and Puma that handle it out-of-the-box for you. But now that we have Ractors, let’s try to convert this into a full-fledged concurrent web server. The first thing we’ll do is to create a queue for incoming requests so that the worker ractors can pick up incoming requests directly from a common source:
queue = Ractor.new do
loop do
Ractor.yield(Ractor.recv, move: true) # move is set to true so that requests are moved permanently to their handling ractors
end
endNow that we have our queue, let’s build our workforce! Here’s how you can create an array of worker ractors that will pick up requests from the queue above:
# Total number of ractors to be created in the server. This should usually be equal to the number of available cores in the machine's processor
COUNT = 8
workers = COUNT.times.map do
# queue is passed to every ractor to facilitate the transfer of requests
Ractor.new(queue) do |queue|
loop do
# Take a request from the queue
session = queue.take
# Print the request's data
data = session.recv(1024)
puts data
# Respond to the request
session.print "Hello world!\n"
session.close
end
end
endAnd now that we have our workers ready, let’s create the parent ie. the server:
require 'socket'
server = TCPServer.new(8000)
loop do
conn, _ = server.accept
# Move the incoming request to the main queue, from where it will be picked up by a worker ractor
queue.send(conn, move: true)
endThat’s pretty much it. Let’s bring all of the code in place and have a look:
require 'socket'
# The requests' queue
queue = Ractor.new do
loop do
Ractor.yield(Ractor.recv, move: true)
end
end
# Number of running workers
COUNT = 8
# Worker ractors
workers = COUNT.times.map do
Ractor.new(queue) do |queue|
loop do
session = queue.take
data = session.recv(1024)
puts data
session.print "Hello world!\n"
session.close
end
end
end
# TCP server instance
server = TCPServer.new(8000)
loop do
conn, _ = server.accept
queue.send(conn, move: true)
endThat’s it! We have our concurrent web server up and running, with nothing but a generic TCP server and some Ractor magic! There’s still room for a lot of improvements in areas like ractor lifecycle management, request parsing, etc, but they are out of the scope of this post.
Recap
In this article, we began by looking at the origins of Ruby Ractors, when they were conceptualized by the name “Guilds”. We understood the various details of the initial proposal, which turned out to be key factors in determining the structure and functionality of the latest addition to the Ruby language. Once we were thorough with the concept, we took a glance over the probable reasons why the name was changed. Also, to be sure, we contrasted between the two different-named versions and concluded that apart from the name, and the fact that one was a concept and the other is an implementation, nothing else has changed between the two.
Finally, we set down to understanding how Ractors work, by beginning from a basic, empty ractor to a full-fledged, concurrent web server built using Ractor. This sums up our journey into the multi-threaded universe of Ractors. For more of such in-depth content around web development, and a solid tool for optimizing your application’s performance, feel free to navigate around our website and our blog!




