LinuxのCPUロードを理解する - どのような時に気を付けるべきか。
すでにLinuxのロード・アベレージのことを、よくご存知かもしれません。ロード・アベレージはuptimeとtopコマンドで表示される3つの数字です。下のように表示されます。
大多数の人は多かれ少なかれ、ロード・アベレージとは何かを知っているでしょう。
3つの数字は、段階的な期間(1分、5分、15分の平均)での平均を表しています。数字が小さいほど良いことを示しています。大きい数字は、何か問題があるか、マシンの過負荷を意味します。しかし、しきい値は何でしょう?どんな時にロード・アベレージを気にしなければならないのでしょうか、そして、どんな時に緊急で、できるだけ早く解決するべきなのでしょうか?
最初にロード・アベレージの意味について簡単に背景を説明します。最も簡単な例から始めましょう:一台のマシンに、シングル・コアのプロセッサが搭載されている場合です。
トラフィックの例え
シングル・コアのCPUは言わばシングル・レーンのトラフィックです。あなたが橋の管理者だったとします。時々橋は非常に混雑して、渡るために車が列を作っています。橋のトラフィックがどんな状況か人に伝えたいときに、ある時間に何台の車が橋を渡るために待っているかというのは、一つの良い指標でしょう。もし待っている車が1台もないのであれば、やってくるドライバーは、橋がすぐに渡れることがわかるでしょう。もし何台か車が待っているのであれば、橋を渡るのが遅れることがわかるでしょう。
さあ橋の管理者さん、いったいどんな数字で表せばよいでしょうか?例えばこれではどうでしょう:
0.0は橋に全く車がないことを意味します。 実際のところ、数字が0.0から1.0の間であれば、待っている車はなく、来た車はそのまま通過できます。
1.0は橋がちょうど容量いっぱいであることを意味します。まだ何の問題もありません。しかし、もう少し混雑すると、通過するのが遅れるようになるでしょう。
1.0より大きい場合、待っている車がいることを意味します。どのくらい?ええと、例えば2.0は車の台数がレーン2本分であることを意味します。1レーン分の車は橋を通過しています。もう1レーン分の車は待っています。3.0は車の台数がレーン3本分であることを意味します。1レーン分の車は橋を通過しています。もう2レーン分の車は待っています。という具合に増えていきます。
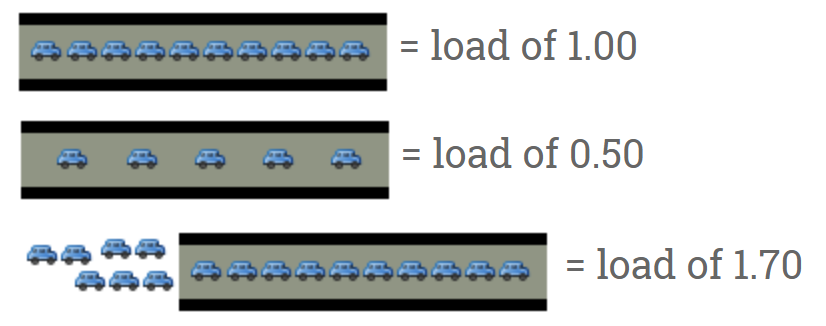
基本的にはこの数字がCPUロードの意味です。”車”はCPUのタイム・スライスを使っている(“橋を渡っている”)か、CPUを使うために待機しているプロセスです。UnixはこれをRun Queue Lengthとして参照していています:現在実行されているプロセス数に加え、実行されるのを待っている(queueに入っている)プロセスの合計です。
橋の管理者だとしたら、決して車/プロセスを待たせたくないでしょう。したがって、CPUロードは理想的には1.0以下にとどめるべきです。また、一時的に1.0を上回っても、短い期間で戻るなら、まだ問題ないと考えるでしょう。しかし、常に1.0を上回っている場合には気にしなければなりません。
ということは、理想のロードは1.0ということですか?
ええと、必ずしもそうではありません。ロードが1.0ということは、余力がないので問題です。実際には、多くのシステム管理者が、0.7で線を引いています。
■“調べる必要がある” 基準:0.70 もしロード・アベレージが>0.7より大きければ、状況がより悪くなる前に、調査を開始する時です。
■“すぐに解決する” 基準:1.00 もしロード・アベレージが1.0より大きければ、今すぐに問題を調べて、解決してください。
■“あー、今深夜3:00だよ。なんてこった” 基準:5.00 もしロード・アベレージが5.0より大きければ、深刻なトラブルが起きている可能性があります。マシンはハングしているか重くなっています。深夜や、カンファレンスでのプレゼンテーション中など、考えうる最悪の時間に(なぜか)起こります。そうならないようにしましょう。
マルチプロセッサの場合はどうなのですか?ロードは3.0なのに、正常に動作しています!
クアッド・コアのCPUを使っていますか?3.0でもまだ正常です。
マルチ・プロセッサのシステムでは、使用できるプロセッサ・コアの数にロードは比例します。”100%の使用”を示す値はシングル・コアのシステムでは1.0、デュアル・コアでは2.0、クアッド・コアでは4.0という具合に増えていきます。
橋の例に戻ると、”1.00”というのは正に、”1レーン分のトラフィック”という意味でした。1レーンの橋の場合は、いっぱいになるという意味です。2レーンの橋であれば、1.0は50%の容量を使っていることを意味します。--1レーンだけがいっぱいなので、もう一つのレーンは丸ごと空いています。
CPUでも同じことが言えます:1.0のロードは、シングル・コアのマシンを100%使用します。デュアル・コアのマシンでは2.0が100%のCPU使用率です。
マルチ・コア vs マルチ・プロセッサ
CPUロードに関連して、マルチ・コアとマルチ・プロセッサの違いについても説明しましょう。パフォーマンスの観点では、デュアル・コア・プロセッサを1つ搭載したマシンと、それぞれシングル・コアのCPUを2つ搭載したマシンは、基本的に同じなのでしょうか?はい。大雑把に言えばそうです。キャッシュ・メモリの総計や、プロセッサ間通信の頻度など、微妙な点が多くありますが。こういった細かい点があるにもかかわらず、CPUロードの値を増やすという目的のためには、CPUコアの合計数だけが問題で、CPUコアがいくつの物理プロセッサに散らばっているかは関係ありません。
このことから2つの基準が導かれます。
■”CPUコアの数==ロードの最大値” 基準:マルチ・コアのシステムでは、ロードは使用できるコアの数を超えるべきではありません。
■”CPUコアはCPUコア” 基準:CPUコアがどのようにプロセッサに散らばっているかは関係ありません。2クワッド・コア==4デュアル・コア==8シングル・コア、全て8コアとしてロードを計算します。
最初に立ち戻る
uptimeの出力からロード・アベレージを見てみましょう。

これはデュアル・コアでの結果です。余裕があることがわかります。ロードが1.7あたりに達するか、それより高い値に留まらない限り、気にすることはないでしょう。
ここで、3つの値は何のためのものでしょうか?0.65は最後の1分間の平均、0.42は最後の5分間の平均、0.36は最後の15分間の平均です。こんな質問が出るかもしれません:
どの平均値を見るべきでしょうか?1,5,それとも15分?
私が触れた基準(1.00 =すぐ解決、など)には、5分か15分の平均を見るべきです。大雑把に言って、マシンの1分間の平均が1.0以上に跳ね上がった場合でも、まだ大丈夫です。
15分の平均が1.0以上になり、そのままの場合になった時、すぐに取り掛からなければなりません。 (もちろん、記事で述べたように、これらの数はシステムのプロセッサ・コア数で読み替えてください)
コアの数はロード・アベレージの解釈に重要とのことですが、システムのコア数はどうやって知るのですか?
システムの各プロセッサに関する情報を取得するには、cat proc/cpuinfoを実行してください。 注:OSXでは利用できません。代替手段はGoogleで調べてください。単なる数を取得するには、grepとword countを使用して実行してください。 grep 'モデル名' /proc/cpuinfo | wc -l
サーバを増やしますか?それとも速いコードを書きますか?
サーバーを追加すれば、遅いコードの応急処置になるかもしれませんが、 Scout APMを使用すると、非効率的でコストのかかるコードを見つけて修正できます。 N + 1のSQL呼び出し、メモリの肥大化、その他コード関連の問題が自動的に識別されるため、デバッグに費やす時間とプログラミングにかかる時間が短縮できます。
サイトを最適化する準備ができていますか?フリー・トライアルにサイン・アップしてください。
もっと読む
■Wikipedia - A good, brief explanation of Load Average; 数学に少し踏み込みます。
■Linux Journal - very well-written article,この記事やwikipediaよりもより深い説明です。
Linuxのパフォーマンスについてもっと知る
■Understanding Disk I/O - when should you be worried?
■Determining free memory on Linux
Linuxのパフォーマンスについてより詳しくなるためにRSSフィードの定期購読かTwitterをフォローしてください。




