Python Garbage Collection: A Guide for Developers
 Mukul Khanna
on
November 10, 2020
Mukul Khanna
on
November 10, 2020

During the course of execution, software programs accumulate several data objects that serve no purpose in the program and need to be let go. If not dealt with, they can keep eating up memory and significantly hamper performance. Garbage collection is the process of cleaning up all these useless data objects that continue to reside in memory. It frees up the corresponding RAM to make room for new program objects.
There was a time when this had to be taken care of manually, but that isn’t the case anymore. Most programming languages today provide support for automatic garbage collection and have different ways of implementing it. Usually, these languages do a pretty good job of taking care of the behind-the-scenes memory management, and therefore do not require any intervention. However, understanding the workings of the principles deployed in these systems enables us to write code that is efficient and takes advantage of the underlying implementations.
In this post, we’re going to explore the mechanics of garbage collection in Python. Python has its own setup for program cleansing that uses a combination of reference counting based methods and generational garbage collection. In this regard, Python offers a lot of flexibility in how it includes support for automatic, as well as manual garbage collection. We will learn more about all of this in great detail in the coming sections, with lots of supporting examples. Towards the end of the post, we will also discuss certain best practices for memory optimization to keep in mind when developing Python applications.
Here’s an outline of what we’ll be covering so you can easily navigate or skip ahead in the guide:
- An Overview of Python Memory Allocation
- How Garbage Collection Works in Python
- Reference Counting
- Reference Cycle
- Generational Garbage Collection
- Manual Garbage Collection
- Time - based Garbage Collection
- Event-based Garbage Collection
- Disabling Garbage Collection
- Reference Counting
- Best Practices for Optimizing Memory in Python
- Recap & Closing Thoughts
Let’s get started!
An Overview of Memory Management in Programming Languages
Before we dive into the nitty-gritty of how garbage collection is orchestrated in Python, let’s take a step back and revisit some of the basics of memory management in programming languages.
As you’d probably know, your code consists of all kinds of data objects - from strings, integers, and booleans to lists, sets, hashes, and more. Each object your code utilizes needs to be stored in memory for your program to be able to work with it.
Even though there was a time when all memory management had to be done manually, today, most programming languages can take care of the corresponding memory allocations and deallocations, without the developers having to worry about the underlying mechanisms at work. Automated memory management has therefore made it significantly easier for developers to focus on the more important aspects of writing software programs - the logic and functionality.
Garbage Collection
We’re going to focus on the part of the memory management system that deals with the deletion of data objects that are no longer in use and correspondingly freeing up memory, commonly referred to as garbage collection.
As you might have noticed, not all variables in your application are required throughout the entire course of its execution. Objects that don’t need to be accessed by your program in the future can be released, and the corresponding memory they have been taking up can be reclaimed for other purposes. Thanks to automatic garbage collection implemented in programming languages, developers don’t need to manually delete objects from memory. Had that been the case, it would have opened up your code to lots of bugs, like dangling pointers and double-free bugs where the memory is either freed without removing the pointers to it or freed twice, likely deleting reassigned objects. Therefore, it is better to have a systematic implementation in place that can intelligently free up memory space. This is because if these objects aren’t cleared from memory, they can keep on accumulating and degrade system performance over time, leading to what is commonly known as a memory leak.
There are many different ways to implement garbage collection, such as tracing, reference counting, escape analysis, timestamp and heartbeat signals, etc. Different languages rely on different implementations for garbage collection, for example, some have it integrated with their compiler and runtime systems, while others have a post-hoc setup that might even require recompilation. In Python’s case, the garbage collector uses the reference counting based method. It runs during the program’s execution and gets to work when an object’s reference count reaches 0. We’ll dive deeper into the details of this in an upcoming section.
If the advantages of automatic garbage collection mechanisms are not already clear, here are the most important ones, summarized in bullet points.
Advantages:
- No (error-prone) manual intervention required
- Robust setup that saves from bugs like dangling pointers and double-free bugs
- Reduced chances of memory leaks
However, it is also important to be cognizant about the caveats and tradeoffs this automation brings to the table. The ease of not having to manually delete objects comes at the cost of overhead - additional resources are consumed and therefore, performance can take a hit. Another issue with this is that sometimes these implicit memory reclamation calls can be slightly unpredictable and can cause your program to suffer from sporadic pauses and interruptions, which can be unacceptable in real-time applications.
Disadvantages:
- Consumes additional resources, impacts performance
- Possible stalls in program execution
Therefore, the goal has been to make sure that garbage collection happens in the background, on a separate thread, in a way that minimizes “stop-the-world” stalls in your program execution. Moreover, it is important to strike the right frequency of garbage collection - too high or low can affect performance.
Now that we have gone through the basics of memory management and garbage collection in programming paradigms, let’s narrow our focus down to how Python recycles its garbage behind the scenes.
How Garbage Collection Works in Python
Python’s garbage collection setup primarily utilizes the reference counting method, i.e. it uses the count of an object’s references to determine whether it should be deleted or not. Let’s dive deeper into the mechanics of reference counting.\
Reference Counting
Each object or variable in your Python code is tracked for the number of times it has been referenced in the program. This reference count goes up whenever the variable is referenced and goes down each time it is dereferenced. Once this count reaches 0, Python is happy to delete that variable from your system’s memory and reclaim the blocks it had been holding up. Thanks to Python’s sys module, we can access an object’s reference count using the sys.getrefcount( ) function. Let’s play around with it using the Python Shell in our terminal.
>>> import sys
>>> my_str = "Hello world!"
>>> sys.getrefcount(my_str)
2You must be wondering why the reference count is being output as 2, and not 1.
This is because my_str being passed to the getrefcount function (line 3) also counts as a reference. Below are two simple examples of referencing a variable, and how they increment the reference count:
>>> my_arr = []
>>> my_arr.append(my_str) # appending to an array
>>> sys.getrefcount(my_str)
3
>>> my_dict = {}
>>> my_dict['my_str'] = my_str # adding to a dictionary
>>> sys.getrefcount(my_str)
4Since the my_str variable was accessed to be added to the array and the dictionary, we can see that the reference count has incremented. Now if we were to reset the array or the dictionary, or replace their contents, the reference count of my_str should decrease.
>>> my_arr = [] # resetting the array
>>> sys.getrefcount(my_str)
3
>>> my_dict['my_str'] = "Some other string"
>>> sys.getrefcount(my_str)
2And as can be seen, that is exactly what happens.
Reference counting is one of the many algorithms used for garbage collection in programming languages. Note that reference counting can not be disabled by your code. However, there is an odd situation where reference counting can be unreliable in garbage collection.
Reference Cycle
In the previous section, we looked at the criteria for an object to be deleted from memory in Python i.e. when the reference count of an object goes to 0, Python makes sure to delete it from the memory. However, in a special (yet common) case where the object has been assigned a reference to itself, the reference count can apparently never go to 0, even if we explicitly delete the object from memory. This is commonly known as a reference cycle.
Below are two examples of situations where the object attains a reference to itself:
>>> my_arr = ['one', 'two', 'three']
>>> my_arr
['one', 'two', 'three']
>>> my_arr.append(my_arr) # appending an array to itself
>>> my_arr
['one', 'two', 'three', [...]]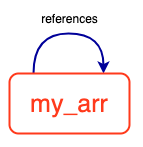
>>> class myClass:
... pass
...
>>> myObj = myClass()
>>> myObj.my_prop = myObj # property of object is object itselfIn these cases, the reference count of the object can never go down to 0 because it has a reference to itself. This can also be witnessed in a situation where there are two (or more) objects that are referencing each other.
>>> my_dict1 = {}
>>> my_dict2 = {}
>>> my_dict1['dict2'] = my_dict2
>>> my_dict2['dict1'] = my_dict1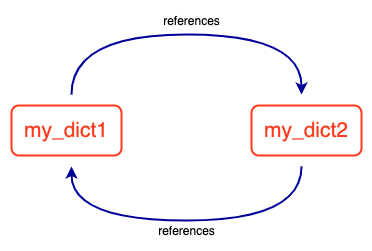
Since both objects are referencing each other, their least reference count is always going to be 1. In the above examples, even if we manually delete the objects using the del command in Python, they will not have cleared from the memory. Let’s verify this for the previous example using an interesting hack. Huge shoutout to Artem Golubin’s awesome blog post on Python’s Garbage Collector for helpful code snippets sourced below
>>> import ctypes
>>> # this class will allow us to access the object from memory (even after it is deleted)
>>> class PyObject(ctypes.Structure):
... _fields_ = [("refcnt", ctypes.c_long)]
...
>>> my_dict1 = {}
>>> my_dict2 = {}
>>> my_dict1['dict2'] = my_dict2
>>> my_dict2['dict1'] = my_dict1
>>> obj_address = id(my_dict1) # getting memory address to track memory block
>>> obj_address
140730947714976
>>> del my_dict1, my_dict2 # deleting both objects
>>> print(PyObject.from_address(obj_address).refcnt) # fetching obj from memory and printing it's reference count
1As you can see, even though we manually deleted the reference cycle objects, they are still not off the memory. This is because the reference count remains 1, as they are still referencing each other. Therefore, with the current method, the corresponding memory allocated to such objects will never be freed, which is obviously bad for your program. And clearly, classical reference counting methods alone can not detect such reference cycles and do not have the solution to this.
Let’s look at what Python has to offer for developers to get rid of reference cycle variables and manually garbage collect objects.
Generational Garbage Collection
In addition to the real-time, automatic reference counting based implementation, Python also provides an in-built gc module that works on the principles of generational garbage collection. This API not only detects reference cycles like the ones we saw above, but also provides developers with more control over the garbage collection process.
Generation-based classification
This method gets its name from classifying objects in your code into three generations. Each object starts out at the first generation and moves to higher generations each time it survives a garbage collection step. For example, if a garbage collection call is invoked (either manually or automatically) for the first time, and your custom object is not cleared, it moves up the generation ladder and is assigned the second generation, and eventually the third generation, if it survives another collection step.
This generation-based classification allows the collector to target the newer, first-generation objects more than the older generation ones. Because the newer objects are more likely to “die young”, this makes the overall process much more efficient and less time and resource consuming. Apart from this, the gc module also lets you configure various parameters that determine the threshold beyond which garbage collection will be automatically initiated. We’ll learn more about this in a later section of the post.
Detecting and Solving the Reference Cycle issue
More importantly, this approach can detect and solve the reference cycles that we discussed above. The cycle-detection algorithm was introduced in Python 1.5 and keeps track of container objects i.e. objects that can hold other objects (eg. lists, dictionaries, classes, etc.) because only they are capable of creating such reference cycles.
Let’s see how we can use this to our advantage. We’ll use the previous example to show how gc can help us garbage collect reference cycle objects using the gc.collect( ) function, which we will explore in greater detail in the next section.
>>> import gc # importing gc module
>>> import ctypes
>>> # this class will allow us to access the object from memory (even after it is deleted)
>>> class PyObject(ctypes.Structure):
... _fields_ = [("refcnt", ctypes.c_long)]
>>> # creating a reference cycle
>>> my_dict1 = {}
>>> my_dict2 = {}
>>> my_dict1['dict2'] = my_dict2
>>> my_dict2['dict1'] = my_dict1
>>> collected = gc.collect() # using gc to garbage collect reference cycle objects
>>> print("Garbage collector: collected {} objects.".format(collected))
Garbage collector: collected 0 objects.
>>> obj_address = id(my_dict1) # getting memory address to track memory block
>>> obj_address
140626355599792
>>> print(PyObject.from_address(obj_address).refcnt) # fetching obj from memory and printing it's reference count: reference count initially
2
>>> del my_dict1, my_dict2
>>> print(PyObject.from_address(obj_address).refcnt) # reference count after deletion
1
>>> collected = gc.collect() # using gc to garbage collect reference cycle objects
>>> print("Garbage collector: collected {} objects.".format(collected))
Garbage collector: collected 2 objects.
>>> print(PyObject.from_address(obj_address).refcnt) # reference count after gc is invoked
0As you can see, only after the gc.collect( ) call was made, did the reference cycle objects’ reference count go to 0, and get deleted from memory.
Python’s reference counting based method is automatic and occurs in real-time, whereas the operations of the generational garbage collection module are periodic, and can be invoked manually. Let’s look at what else we can achieve using the gc module.
Garbage Collection Thresholds
Remember, how we spoke about objects being assigned a generation value based on the number of garbage collection processes they had survived. To specify the collection behavior, the gc module provides three threshold values (one for each generation) that determine a limit beyond which the collection process will be initiated automatically.
Let’s look at the predefined threshold values using the gc.get_threshold() function:
>>> import gc
>>> gc.get_threshold()
(700, 10, 10)We can also look at the current number of objects residing in memory using the gc.get_count() function -
>>> gc.get_count()
(628, 9, 0)As you can see, even without initializing any variables, the first generation object count is already at 628! Let’s try to manually invoke the collection and see what difference it makes:
>>> gc.collect()
0
>>> gc.get_count()
(18, 0, 0)The first generation object count came down from 628 to 18. That’s a huge difference!
If you want, you can also change these thresholds using the gc.set_threshold() function.
>>> gc.set_threshold(800,20,20)
>>> gc.get_threshold()
(800, 20, 20)Each time before a new object is initialized, this count is checked. If the threshold number of objects is already allocated a place in the memory, the garbage collection process is performed, and then the new object is instantiated.
The Tradeoff
Interestingly, these thresholds bring forth a tradeoff that developers need to consider while writing Python applications.
The intermittent garbage collection processes in your program can be resource extensive and sometimes cause your application to pause or stall. However, if not collected enough, these garbage objects can take a toll on performance. For example, increasing the threshold counts decreases the frequency of the collection process. This means that now, your program will pause less often to collect and therefore be less of a pain. But this also means that garbage objects in your program would stay in memory for longer, likely affecting performance. Therefore, it is important to understand this tradeoff, and make a decision based on what suits your application better.
Manual Garbage Collection
However, instead of only letting the threshold count determine the frequency of garbage collection, developers also have the option of manually initiating the collection process based on their own criteria. There are two types of manual garbage collection strategies that are commonly used - (i) time-based and (ii) event-based.
Time - based Garbage Collection
Time - based methods refer to implementations that initiate the garbage collection at regular, predetermined time intervals. This allows developers to choose the time at which they want the collection to happen. For example, based on analytics information from the website’s traffic trends, it’s developers can choose a good time slot during which a minor pause won’t make much of a difference to the application’s usage.
Event-based Garbage Collection
Event-based methods on the other hand initiate garbage collection when a certain event takes place. You can think of it as an if condition block sitting somewhere in the code that checks for the occurrence of an event (probably through a corresponding boolean variable), and executes the garbage collection command accordingly. For example, you might want the collection to happen when a database operation is made, or when the user refreshes a page, or logs out, or exits the application, or any other event that would seem like a good occasion to clear out some waste objects from memory.
Disabling Garbage Collection
Even though reference counting can’t be disabled in Python, the generational garbage collection module can be. It is possible to disable the gc module by setting the threshold counts to (0,0,0). This is something that the Instagram team did, after properly studying the internals of their Django based application and realizing that the gc module created memory issues for their master-worker architecture. Only because this change resulted in a 10% speed improvement in their widely used application, is such an intrepid endeavor easily justified.
However, for most cases, turning off the gc collector will not be necessary. Only if you have a proper understanding of the problem at hand, and how the mechanics of the default, in-built garbage collection affect your case, should you consider making such a decision.
Avoid Playing with Default Garbage Collection Behavior
For most projects, however, it would be unwarranted to mess with the default garbage collection behavior. Python thrives off of the productivity that it allows its developers to leverage - it lets developers focus on the higher-level program logic, without having to worry about the lower-level details. Therefore, it might be more advisable to let Python take care of its internals - the default garbage collection implementation is capable enough to look after most memory issues.
It is also important to note that these internal defaults are “defaults” for a reason. Over the years, maintainers and contributors of the language have funneled their experience into determining defaults and implementing internal systems for Python that are the most optimal for the majority of cases, in a way that requires the least intervention.
Likewise, if you find your project under-performing and running low on resources, instead of fidgeting too much with the internals of garbage collection, a better option might be to upscale or upgrade your compute resources. The time and resources spent on fixing internal garbage collection issues can likely be saved by spending a little extra on upgrading your compute.
To learn more about how memory is managed in Python, feel free to check out our blog post on Memory Management in Python.
Now that we’ve covered all about garbage collection in Python, before we close, let’s go through certain best practices that you might want to consider for optimizing memory while developing Python applications.
Best Practices for Optimizing Memory in Python
1. Be Intelligent About Your Data Structures
In Python and most other programming languages, certain decisions related to the choice of data structures and how you manipulate and work with them can make a significant difference to your program’s performance.
Use Generators, Not Lists for Big Arrays
Python generators are much more memory efficient as compared to lists. This is because when working with lists, Python loads all the elements into memory, all at once. Generators, on the other hand, perform lazy evaluation i.e. they’ll return (yield) one element at a time, and therefore don’t need to load the whole sequence into memory at once. Instead, they generate only the immediately next element of the sequence at a time. Using generators, therefore, is especially important when working with big arrays, and saves you a whole lot of memory.
Use Numpy (or similar libraries) for Extensive Mathematical Operations
If your program involves large numerical arrays and matrices, or extensive mathematical operations like matrix arithmetic, for example, for data science/machine learning projects, you should use libraries like Numpy, Scipy, or Pandas. This is because these libraries are developed to be extremely memory efficient and optimized in how their underlying lower-level code performs heavy mathematical operations. For instance, writing Python code that utilizes Numpy broadcasting is definitely going to be cleaner, more memory efficient, and faster as compared to what you end up writing for the same case from scratch.
Avoid Using ‘+’ Operator to Concatenate Strings; Use String Formatting Instead
Another small tip to keep in mind is to avoid using the ‘+’ operator to concatenate and generate long strings. The reason for this is that strings are immutable in Python. For every ‘+’ operation in your statement, Python will create a new string in memory for the string pairs concatenated from left and right. For example, if you were to concatenate four springs like so:
>>> a + b + c + dand if each string has a length of 5, Python will create new strings for:
a + b of length 10
(a + b) + c of length 15
((a + b) + c) + d of length 20with memory being allocated for a total of 45 items, instead of for just one new string -
a + b + c + d of length 20The better alternative is to use Python’s string formatting using the % syntax or the .format( ) function, like so:
>>> "{}{}{}{}".format(a, b, c, d)This turns out to be much more memory efficient for your code as compared to the previous ‘+’ based concatenation.
2. Use built-in Tools and Functions
Python offers a bunch of in-built utility functions that sometimes developers are not aware of. These in-built utility functions are much more memory efficient as compared to their naively written custom counterparts. For example:
Python’s map function
If you were to convert a list of lowercase strings to uppercase, many developers might run a for loop across the list and thus change each element.
>>> # what not to do
>>> my_list = ['one', 'two', 'three']
>>> my_new_list = []
>>> for item in my_list:
... my_new_list.append(item.upper())A more efficient, and tidier alternative is to use the map function, and then converting it to a list if you want, as shown below:
>>> # what to do instead
>>> my_list = ['one', 'two', 'three']
>>> my_new_list = list(map(str.upper,my_list))This not only saves you two lines of code, but also is much more memory efficient; even more so for large data sequences.
Python’s itertools
Python’s itertools module provides a lot of helper functions to deal with loops in a way that is more memory efficient and easier to work with. Let’s see this through an example:
If you were to generate all the unique 2-pair combinations of items in a list, there are two ways of doing this in Python - (i) using a conventional nested for loop:
>>> my_list = ['stone', 'paper', 'scissors']
>>> for i in range(len(my_list)):
... for j in range(i + 1, len(my_list)):
... print(my_list[i], my_list[j])
...
stone paper
stone scissors
paper scissorsand (ii) using an itertools’ combinations() function:
>>> from itertools import combinations
>>> my_list = ['stone', 'paper', 'scissors']
>>> for c in combinations(my_list, 2):
... print(*c)
...
stone paper
stone scissors
paper scissorsYou can clearly see how much simpler the latter approach is. More importantly, using the combinations() function, the time complexity is much less because it only uses a single for loop, as opposed to a nested for loop in the former method. This difference can pay huge dividends in terms of saving memory resources when working with larger lists.
3. Analyze your code
To be able to squeeze every ounce of performance from their apps, it is important for developers to analyze various aspects of their code - from coverage to memory consumption to quality and performance. Python offers a bunch of native, as well as third-party tools and libraries that can help in evaluating performance. Here are some of them that are worth considering for profiling your Python application -
cProfile: An in-built module that provides information like - total execution time, total and individual function call count, etc. Here’s an example:
>>> import cProfile
>>> def hello_world():
... print("Hello world!")
...
>>> cProfile.run('hello_world')
3 function calls in 0.000 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.000 0.000 <string>:1(<module>)
1 0.000 0.000 0.000 0.000 {built-in method builtins.exec}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}memory_profiler: As the name suggests, this Python module allows monitoring of the memory consumption of a process, as well as a line-by-line analysis of memory consumption for Python programs.
objgraph: Objgraph is a module that provides interactive visualizations for object graphs in Python (example image below). This helps in the identification of the most memory-consuming objects in your program, as well as information about object references, additions, and deletions.
resource: Resource is an in-built Python module that provides information about the system resources utilized by your Python code and also allows developers to set constraints on the same.
4. Application monitoring tools: Scout APM
If you’re serious about building Python applications that cater to hundreds or thousands of users, you would definitely need an application monitoring tool in your development toolkit. Application monitoring tools like ScoutAPM allow you to monitor the various aspects of your application’s performance and can effectively pinpoint bottlenecks, memory bloats, N+1 query problems, and many more inefficiencies, inconsistencies, and irregularities in your application’s performance.
With live alerts, real-time insights, and always on, 24x7 support, ScoutAPM enables you to continuously optimize your application as you discover issues that are limiting performance. This ensures that all potential issues are tracked down, debugged, and resolved before the end-users come to notice.
Recap & Closing Thoughts
To recap, we started by revisiting the basics of memory management and garbage collection in programming languages, followed by exploring the methods of garbage collection in Python. We looked at reference counting based methods, reference cycle objects, and the generational gc module. We then looked at two ways of doing manual garbage collection, including time-based and event-based methods. We also discussed how it is less advisable to fiddle with internals of the default collection setup, unless absolutely necessary. Towards the end, we looked at four best practices to consider for optimizing memory in Python applications.
Now that you’ve learned all there is to know about garbage collection and best practices for memory optimization in Python, go ahead and play around with these concepts in your applications. Witness the gc module and it’s collect( ) function in action, and write memory-efficient Python applications. Happy coding!




