Are You Monitoring Your Machine Learning Systems?
We're partnering with FusionCell to survey folks about how they monitor machine learning learning applications. FusionCell's Robert Dempsey joins us today to share some of the personal pain he's faced monitoring machine learning apps. Robert has been helping companies and engineers learn about, build and leverage machine learning systems.
When StackOverflow surveyed 64,227 software developers from 213 countries, Python came out as the programming language most wanted by employers.
Why?
Machine learning, or "ML" for short.
Over the past few years Python has taken over in machine learning thanks to libraries like Pandas and Scikit-learn.
But everything needs time to mature.
When it comes to monitoring machine learning systems, how to monitor them currently consists of gluing together many pieces of tech.
Is there a better way to hunt down and eradicate the bottlenecks in your ML systems?
There may be. But we need your help to do so.
Here's why...
The Case for Monitoring Our Apps In Production
I probably don't have to sell you on why monitoring production applications is important, but just for fun let's look at three typical scenarios where it really helps:
- You've had to spend a late night or three fixing some part of your data pipeline
- You've been asked by a manager why the system seems slow to gather or process data
- You've had to suddenly process more data without throwing more hardware or money at the problem
- If you can relate to any of these, you understand how important performance monitoring is.
With a machine learning system it can be a tricky proposition because of all the moving parts...
Tech I've Used in Machine Learning Systems
Every data pipeline I've ever worked on is some variation of this:
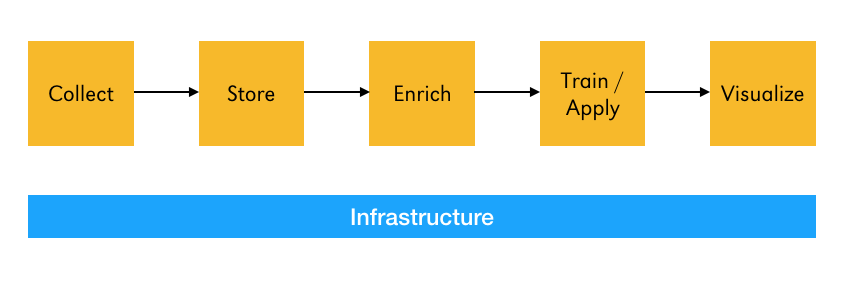
- For data collection I've built APIs with Python, Docker, MySQL, Redis and Kafka.
- To process all that data I've used Kafka, Storm and Spark.
- To store the data I've used Elasticsearch, S3 and HDFS.
- No system is complete without charty goodness. For this I've made heavy use of Kibana.
- To alert me when things went wrong I used PagerDuty.
- To monitoring everything I've used the web UIs available in Spark and Storm, log files stored in Kibana, and created a metric $hit-ton of custom metrics in Datadog.
All that tech brings along some fun challenges...
The Challenges With Monitoring a Machine Learning System
Even the simplest machine learning systems consist of many moving parts. The most basic I've built was deployed to a single server and consisted of:
- A Python application to gather data from multiple databases and internal APIs
- Spark to processes and enrich the data
- A Python application to index the processed data into Elasticsearch
One of the largest I've worked on consisted of:
- A front-end Python API backed by a MySQL (RDS) database
- 50+ Python microservices that gathered data
- A Redis database
- A 5-node Kafka cluster for storing raw and processed data
- A 7-node Storm cluster for enriching data
- An 7-node Elasticsearch cluster for storing data and visualizing it with Kibana
In all cases we had monitoring in place.
But here's the rub - the metrics we used were surface level.
When I had to look at the performance of my code I had to either add timing information to my code and output it to the logs, or profile it locally.
Both of these solutions were non-optimal.
Why?
First I had to roll my own metrics. While I was working with a team and we did code reviews, we didn't always have the luxury of being able to have a considered discussion of what we should be measuring. That means I had to come up with the metrics I thought were best. And while I would love to sit here and tell you my code performs like a champ at all times, that ain't reality, for any of us.
Second, while I develop on a Mac and deploy to Linux, there are other variables in play that could affect my application. How many times has something worked awesome locally only to perform not as well in production? Right. Profiling my code locally can help, but it won't tell me how my code performs in a production environment.
Third, I lacked the full picture. What I was doing was combining surface-level metrics with metrics of the environment my app is running in. That led to some seriously complex dashboards. Our brains are good, but try staring at some 10+ pane dashboard with metrics streaming in and see how long it takes before you go cross-eyed.
These Challenges Aren't Just In Machine Learning Systems
These challenges are present in all Python applications I've encountered.
And that leads to my question - how are you monitoring your Python applications?
I've teamed up with the awesome team at Scout to find out, and we need your help!
Today we're launching our Python Monitoring Survey. You can take the survey here.
The survey will be open from today through the middle of February. The results will be published on this blog in the beginning of March.
Want to be the first to know the results?
Just add your email address at the end of the survey and we'll give you first access to the survey results.
Click here to take the survey today.




